
Resources and insights
Our Blog
Explore insights and practical tips on mastering Databricks Data Intelligence Platform and the full spectrum of today's modern data ecosystem.

Most teams that move to Databricks get the hard part right. They migrate the processing engine, rebuild the transformation logic, and stand up Unity Catalog. Then they leave Azure Data Factory running in the background: connected to everything, owned by nobody, and quietly accumulating cost and complexity. In this entry, that’s the gap we address.
Explore More Content
ML & AI

Unity Catalog commits: Make your managed delta layer safer and more performant
Unity Catalog catalog commits move Delta table commit coordination from filesystem-level operations into Unity Catalog, making UC the authoritative source of table state. This enables strict concurrency control, attribute-based access for external engines, and multi-statement multi-table transactions — while leaving data in open Delta format on cloud storage.

Global Job Parameters, Thanks To DABs Mutators
Declarative Automation Bundles mutators let you define job parameters once in a central config file and inject them into every job automatically at deploy time — no more copy-pasting catalog names, schema paths, and environment variables across your bundle. This post walks through a working implementation with full code examples.

Speaking the Language of Finance: Why Our Databricks BrickBuilder Specialization Matters
Earning a Databricks BrickBuilder Specialization in Financial Services requires more than technical credentials — it demands domain knowledge built across banks, insurers, and investment firms operating under strict audit and regulatory requirements. SunnyData's specialization reflects years of production-ready implementations where data errors have real consequences. For financial services leaders evaluating data partners, it's a signal worth understanding beneath the surface.

Building Production-Ready Databricks Projects with Bundles
Most Databricks teams using Bundles are only scratching the surface. The real value isn't in the deployment syntax — it's in the engineering discipline Bundles makes enforceable: explicit dependency management, reproducible local environments, automated quality gates, and CI/CD as the only path to production. This post breaks down what a production-ready Databricks project structure actually looks like, and the software engineering practices that make it ship with confidence.

Watermark-Based Incremental Ingestion (Lakeflow Connect query-based capture)
Databricks Lakeflow Connect now supports query-based capture — a watermark-based incremental ingestion pattern for teams that can't or won't enable Change Data Feed. Using a cursor column, soft deletes, and optional hard-delete sync, teams can achieve true incremental processing from SQL sources like PostgreSQL, Azure SQL, and MySQL — without a gateway, and without full table reloads that silently drain your compute budget.

From Informatica to Databricks: What Actually Works in Production
Informatica's new LTS pricing means staying put is no longer free — it's a recurring tax on a platform with a shrinking capability roadmap. This guide covers the full migration path from PowerCenter to the Databricks Lakeflow stack: the CFO-ready business case, a construct-by-construct translation guide, and the five-phase M5 methodology SunnyData runs on every engagement. If your team is weighing IICS versus a full re-platform, the architecture decision and cost model are here.

Enforcing Enterprise Naming Conventions in Databricks: The Agentic Way
Naming conventions only work if they're enforced — and a Confluence page nobody reads isn't enforcement. This post walks through using Databricks Workspace Skills to make naming rules executable in Genie Code, then scaling that to a catalog-wide audit agent built with Databricks Apps and DABS. The result is automated, repeatable governance that runs without requiring engineers to opt in.

How to (Efficiently) Process Change Data Feed in Databricks Delta
Databricks AUTO CDC isn't just the easiest way to process Change Data Feed, it's also the cheapest. A benchmark across 25 million INSERT, UPDATE, and DELETE operations found AUTO CDC outperformed Structured Streaming and SQL Warehouse on cost in every run, even as the target table grew to 72 million records. Structured Streaming remains the right choice for custom logic; AUTO CDC wins on standard SCD Type 1/2 patterns at scale.

How to Pass Terraform Outputs to Databricks’ DABS
As teams migrate infrastructure definitions into Declarative Automation Bundles, Terraform still owns the Azure layer — Key Vaults, resource groups, networking. This post walks through a clean, CI/CD-ready pattern for passing Terraform outputs directly into bundle variable overrides, eliminating manual config steps and the environment drift that follows them.

Genie Code Analysis: Two Weeks Later
Databricks Genie Code hit a 77.1% task success rate in production data science workflows — more than double what general-purpose coding agents achieve. But that performance is entirely conditional on the quality of your Unity Catalog metadata. SunnyData's two-week evaluation breaks down what works, what doesn't, and the governance layer you need before you go live.

5 Databricks Patterns That Look Fine Until They Aren't
Five common Databricks coding patterns — including undocumented API calls, manual SparkSession instantiation, and hardcoded Spark configs — that pass code review but fail silently in serverless environments or during platform migrations. For each anti-pattern, this post explains why it breaks and shows the correct native Databricks approach using DABS, the Databricks SDK, and dynamic job parameters.

Databricks Lakewatch: The Future of Agentic SIEM
Databricks Lakewatch replaces the traditional SIEM model with an Open Security Lakehouse — storing 100% of telemetry in open formats at up to 80% lower TCO. AI agents reason across years of unified data to detect and respond at machine speed, closing the visibility gap that legacy SIEMs were structurally forced to create. Early customers include Adobe and Dropbox, with broader availability following Private Preview.

Lakeflow Connect Free Tier: $35/Day Back in Your Budget
Databricks' permanent Lakeflow Connect free tier delivers 100 DBUs per workspace per day — covering up to 100 million records of ingestion at no additional compute cost. For enterprise teams running multiple workspaces, that's over $255,000 in avoided annual costs. This post breaks down the economics, architecture, and what it means for teams still paying a third-party ETL tax.
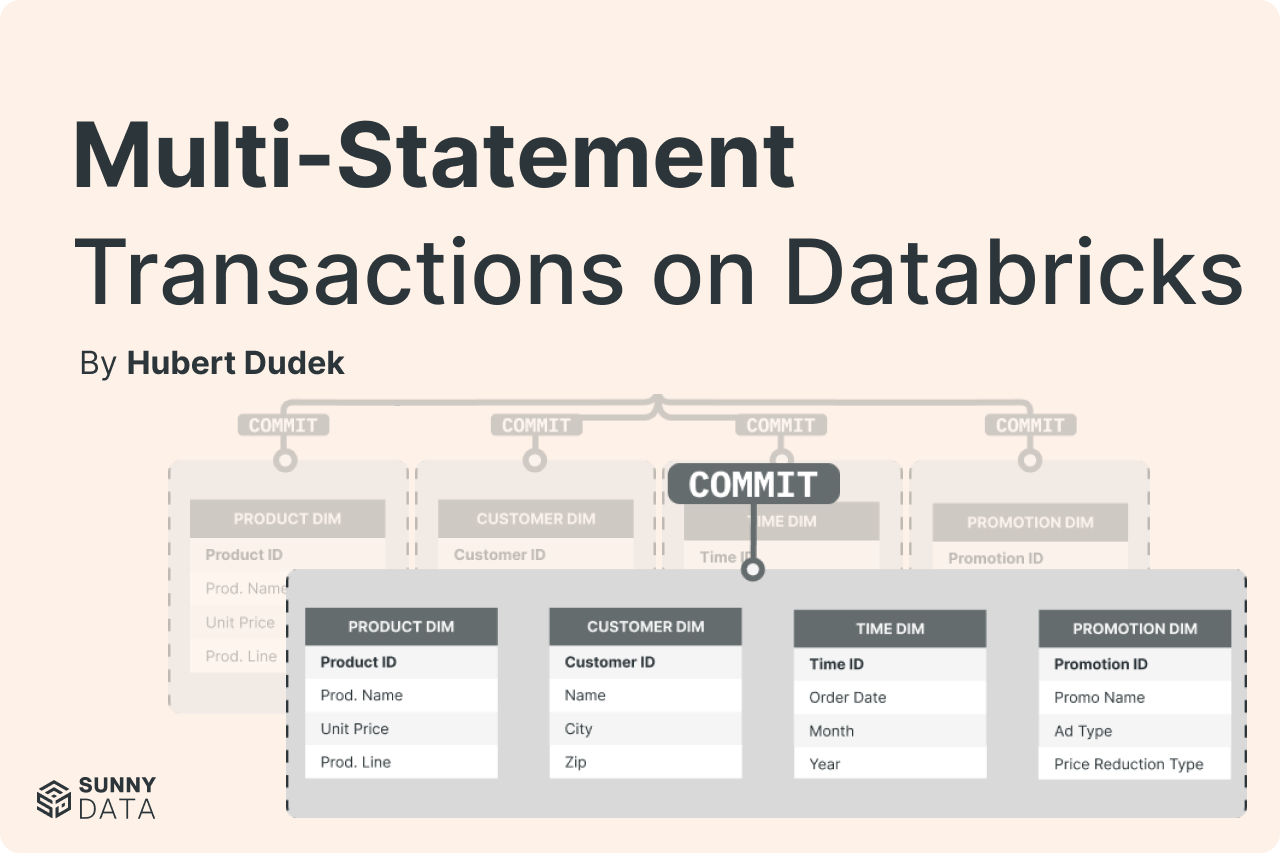
The Lakehouse Finally Has Real Transactions
Learn how Databricks multi-statement transactions use Unity Catalog catalog-managed commits to guarantee atomic updates across multiple Delta tables — with a step-by-step walkthrough.

Why Your Databricks Upgrade Is Incomplete If You're Still Running ADF
Still running ADF after moving to Databricks? Here's why it happens, what it's costing your governance story, and how Lakeflow Jobs closes the gap.