Databricks Genie: Our Experience with & Lessons Learned
Introduction
Only a few months have passed since the public launch of AI/BI Genie, and at SunnyData we have already had the opportunity to work on three different projects with clients from various sectors: banking, industry, and energy. We believe this is the perfect moment to pause and share our experiences—both the positive aspects and the challenges—regarding this new Databricks functionality.
AI/BI Genie and The Path Towards Data Democratization
When we learned that Databricks was developing a feature to converse with your data in a controlled environment, and later had the opportunity to test it, we immediately realized that it would become an essential component of the ecosystem—just as Unity Catalog is for Data Governance. This is because such solutions drive the true democratization of data consumption, breaking down the barriers between technical and business users.
For several years now, BI tool manufacturers have been developing interfaces that allow users to query data using natural language. Although it’s not a new idea, most of these applications did not work very well. However, they already hinted at the direction things were heading and opened the door to a new way of consuming information and resolving our doubts—using our own words.
Make no mistake: traditional reports, especially those of a regulatory or routine nature, will not disappear; however, it is very likely that the classic dashboard concept we know—how we generate and use them—will evolve. In the near future, I have no doubt that we will be able to generate dynamic dashboards based on the topics we wish to address, built on the learned context and enriched with suggestions that the applications themselves will provide (probably even better than our own ideas).
It’s true that we haven’t yet reached that level of perfection in its ultimate expression; however, we are very, very close, and we already see similar approaches emerging, as is the case with AI/BI Genie.
What is Databricks AI/BI Genie? An Overview
At SunnyData, together with our Technical Advisor Josue A. Bogran, we have developed a wide variety of content on AI/BI Genie. We have explored its different facets through several blogs and videos with the Databricks Engineering team. Although this blog does not intend to detail every feature, it is important to understand how this service differentiates itself from its predecessors and how it is positioned in the market to grasp where we stand today.
Source: Databricks
AI/BI Genie not only delivers the precision that its predecessors lacked— thanks to its integration with OpenAI—but it also operates in a secure and controlled environment. It uses the user’s data (and metadata) and specific instructions from the user and each “workspace” as its primary source of responses (we will discuss this later). This is extremely important because it significantly reduces hallucinations without losing the “intelligence” of these systems. In a way, it combines the best of both worlds.
AI/BI Genie is designed to work with multiple “workspaces,” which, in terms accessible to non-technical audiences, equates to different agents focused on a specific purpose. For example, it is possible to create Genie Agents that operate exclusively with certain tables and follow very specific instructions for a user in sector X who works with table Y. This enhances precision and enables even greater specialization among the agents.
Furthermore, there are three key “plus” factors in Genie (in addition to being free and operating on a consumption-based payment model).
First, everything is developed in a secure and controlled environment that not only defines a “learning radius” but also inherits the data governance established at a macro level in Unity Catalog.

Source: Databricks
2. Second, each system response comes with a detailed explanation of how that result was achieved, which is crucial for understanding the underlying logic.
3. And third, building a Genie Agent is very simple and requires minimal time, which facilitates its scalability.
From Theory to Practice: Real-World Implementation of Databricks Genie
Now is the time to share our real-world experience on the battlefield, working with business users who are not data experts and who are unfamiliar with the underlying workings of these systems. First, we will analyze the challenges and lessons learned; then, we will share some useful tips for all readers who are building workspaces in Genie.
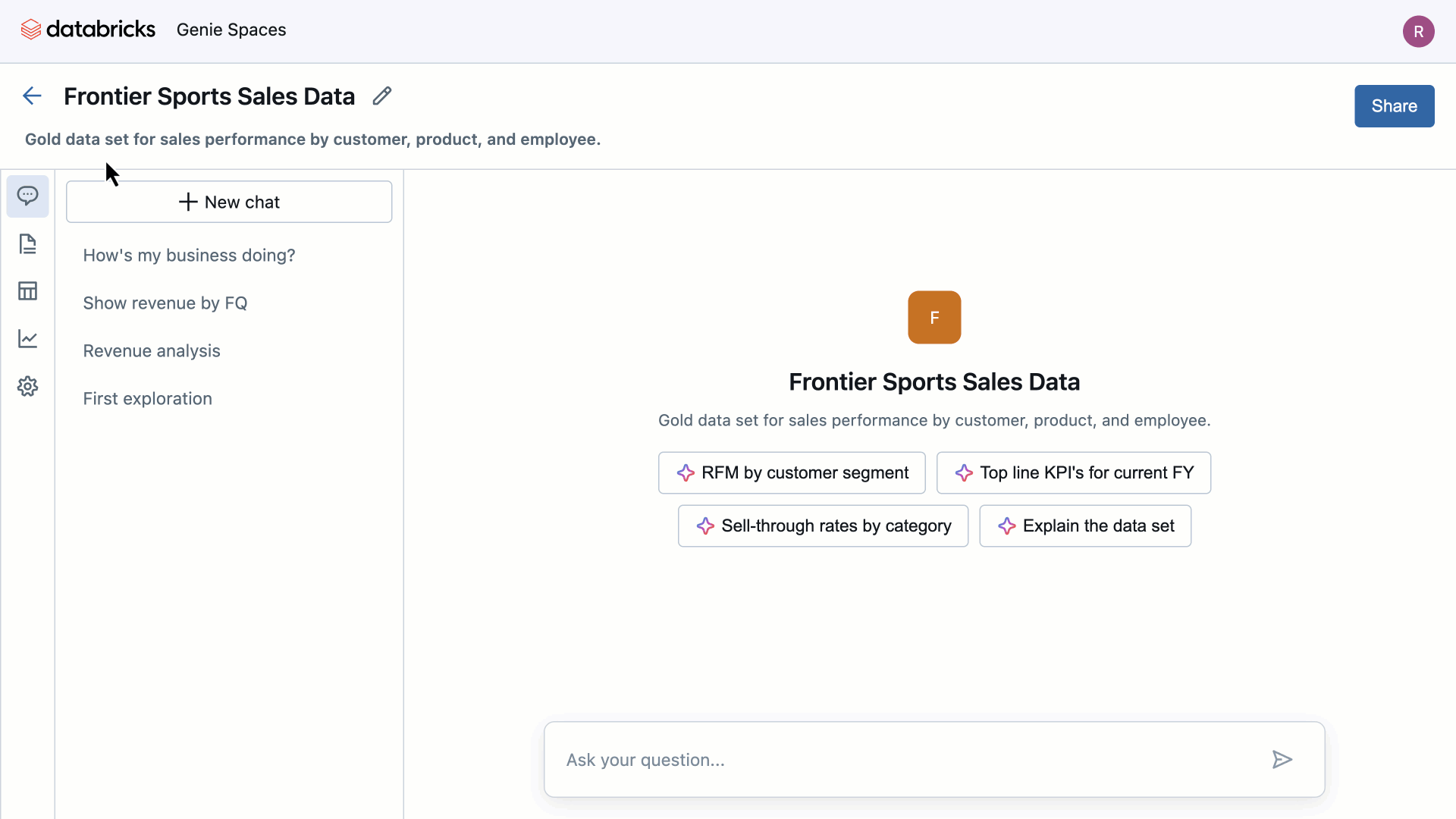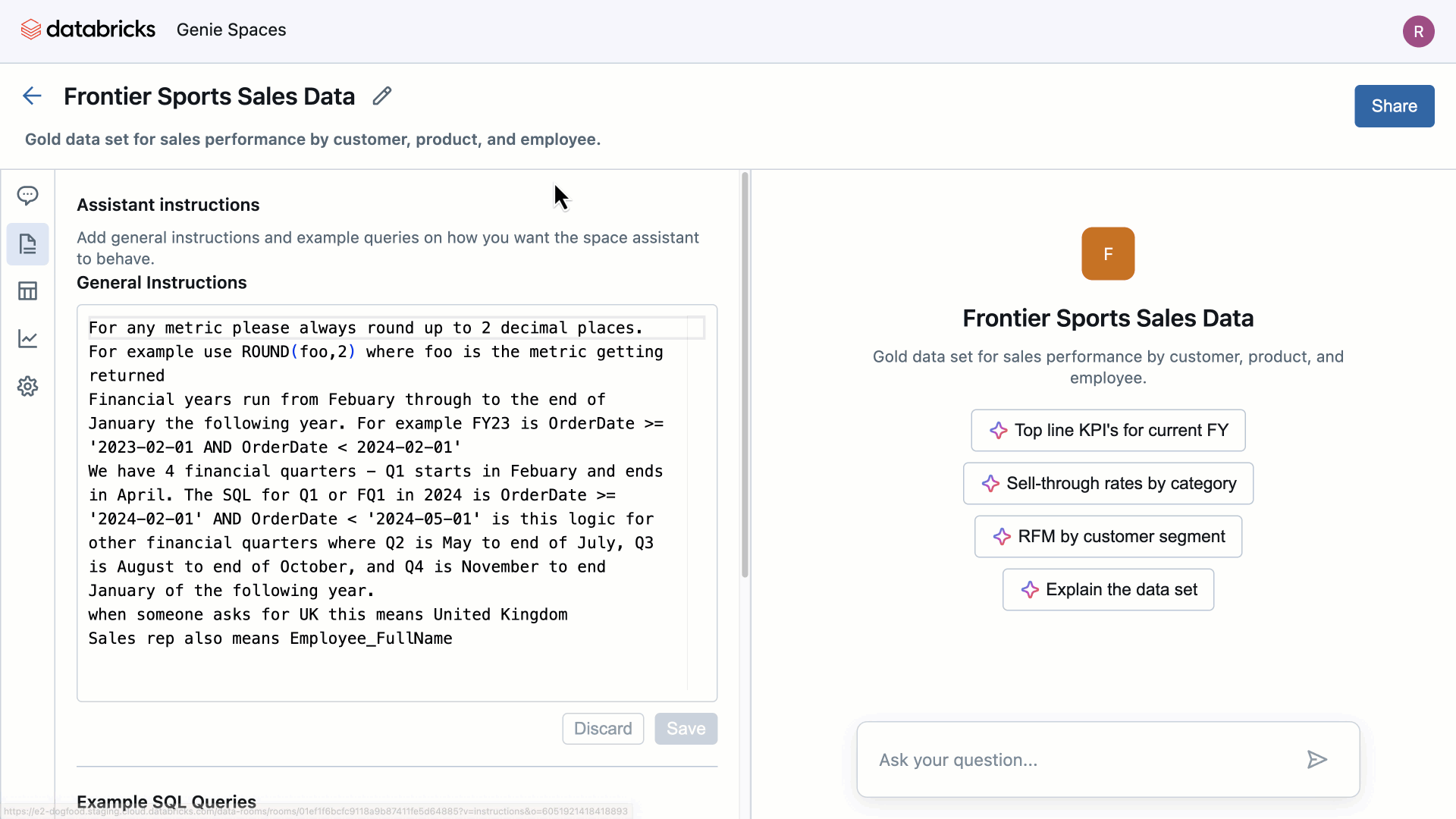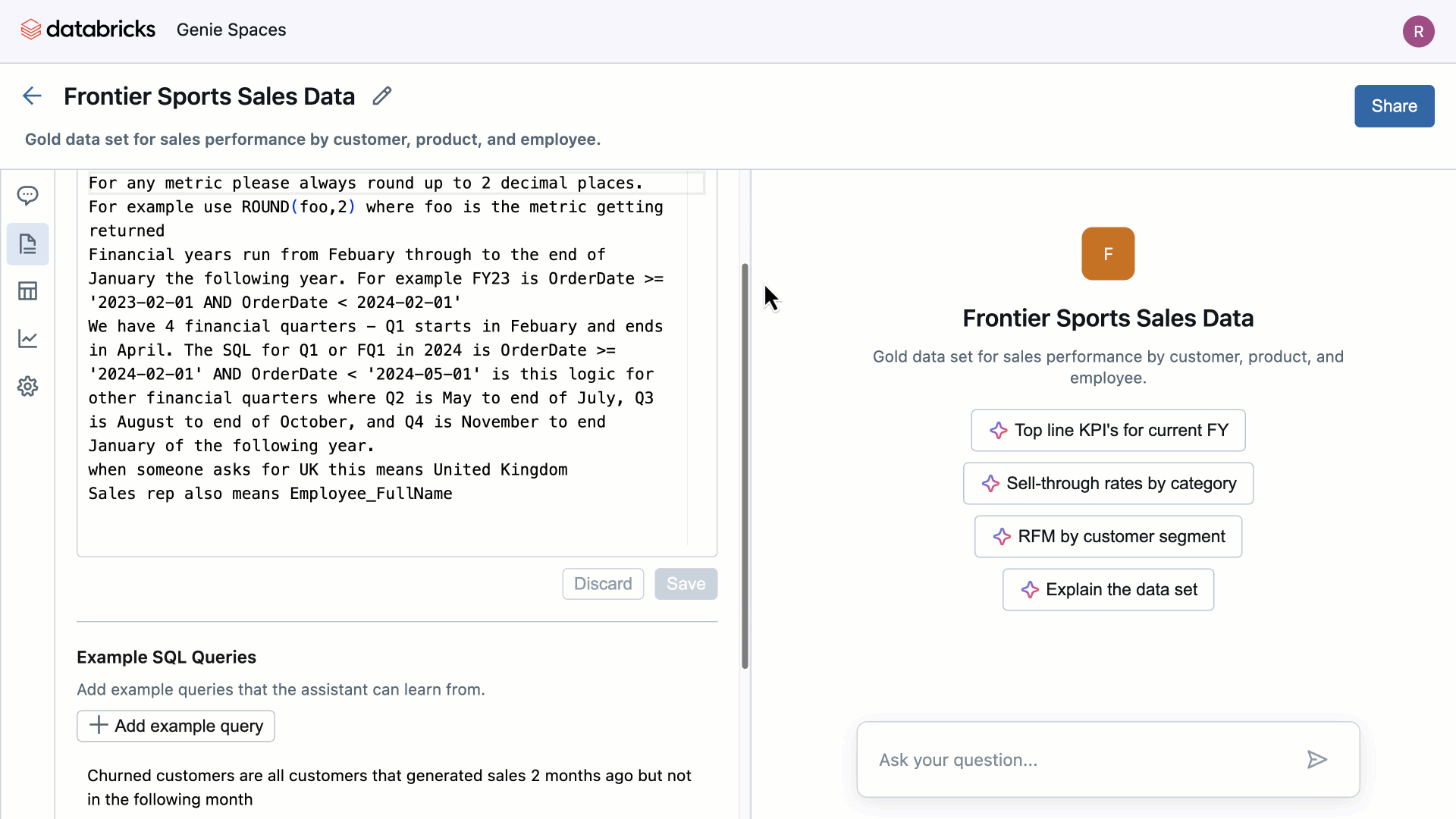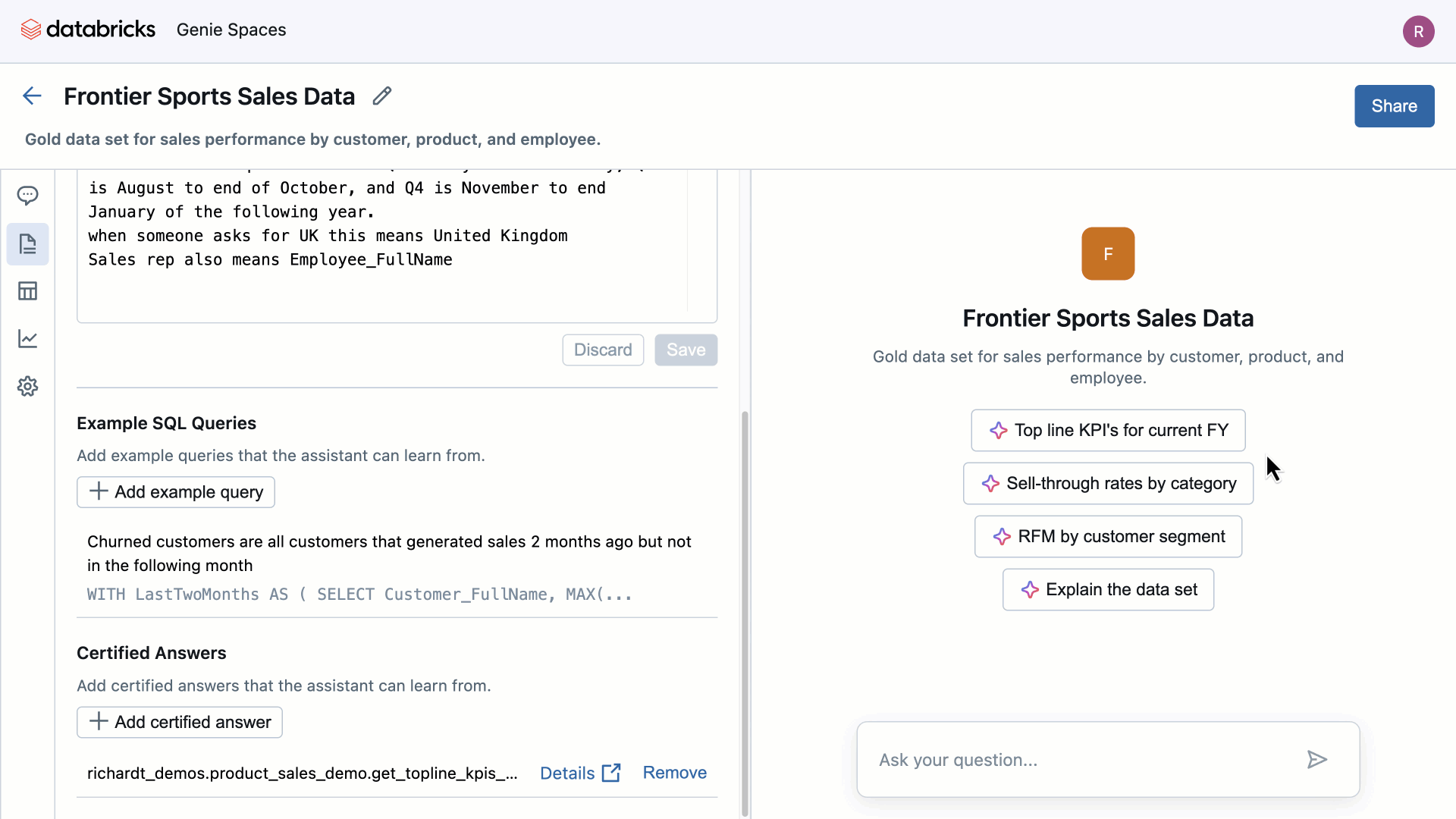
Source: Databricks
Challenges and Lessons Learned
It is important to keep in mind that, as is often the case, there is a significant difference between lab tests and real-world execution—even when the technology operates nearly flawlessly. For example, the range of OpenAI models can address 99% of our daily general information needs. However, this happens in contexts where we, as users, already know how to use the tool, understand its risks, and can guide it.
When these GenAI-powered developments are democratized for third parties—and even more so when used for critical tasks—our trust as developers is immediately diminished, and the challenge takes on a different perspective, especially knowing that the client will be querying critical data, and even the slightest error will undermine confidence in the system.
Consider, for example, a query in the financial realm: “How has the average balance evolved over the last 3 months?” For a financial institution, the answer must be extremely precise and reliable, delivering the same result that a traditional query would yield. This demands that everything is perfectly configured and validated and that the user receives adequate training to understand the application.
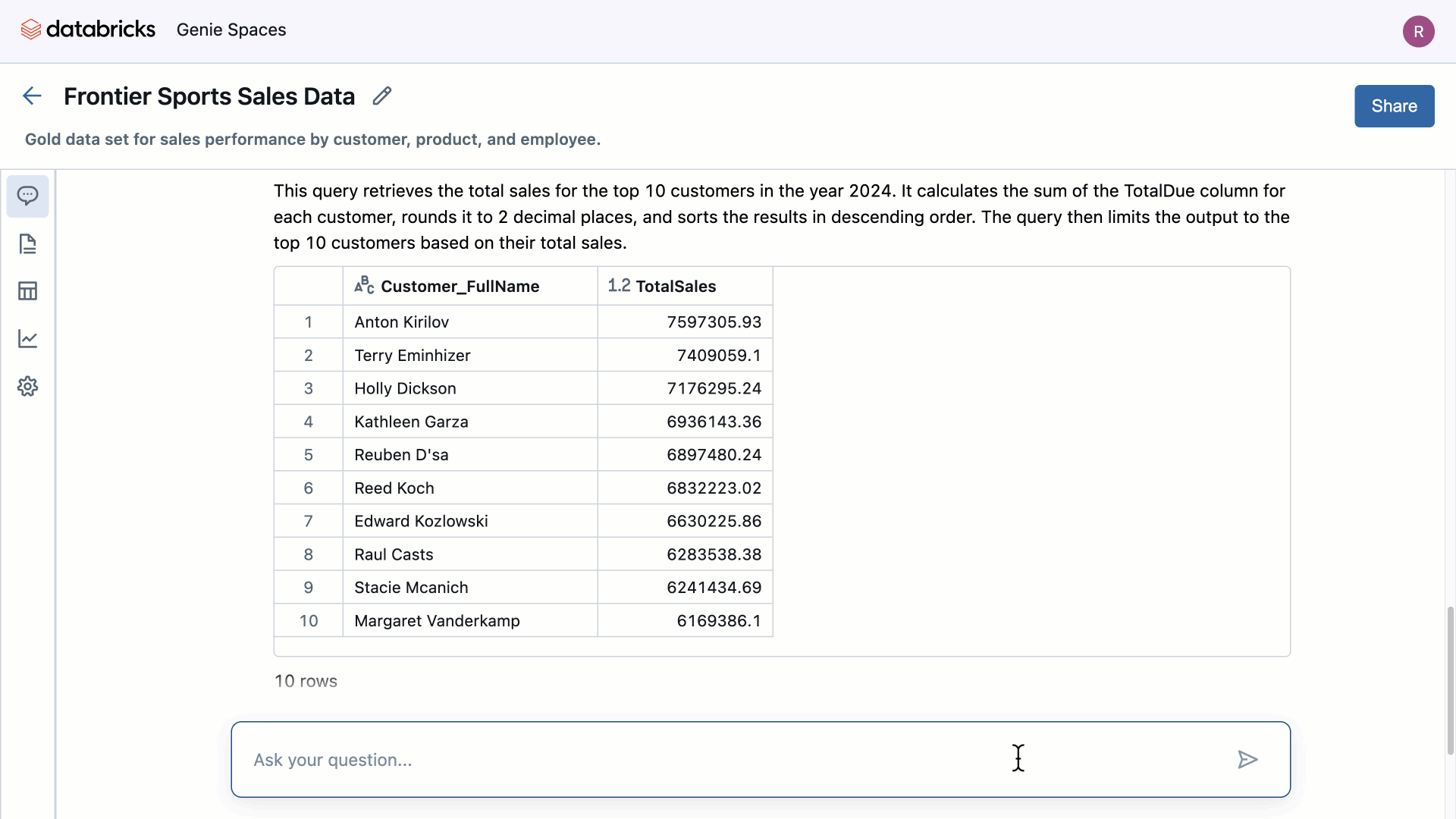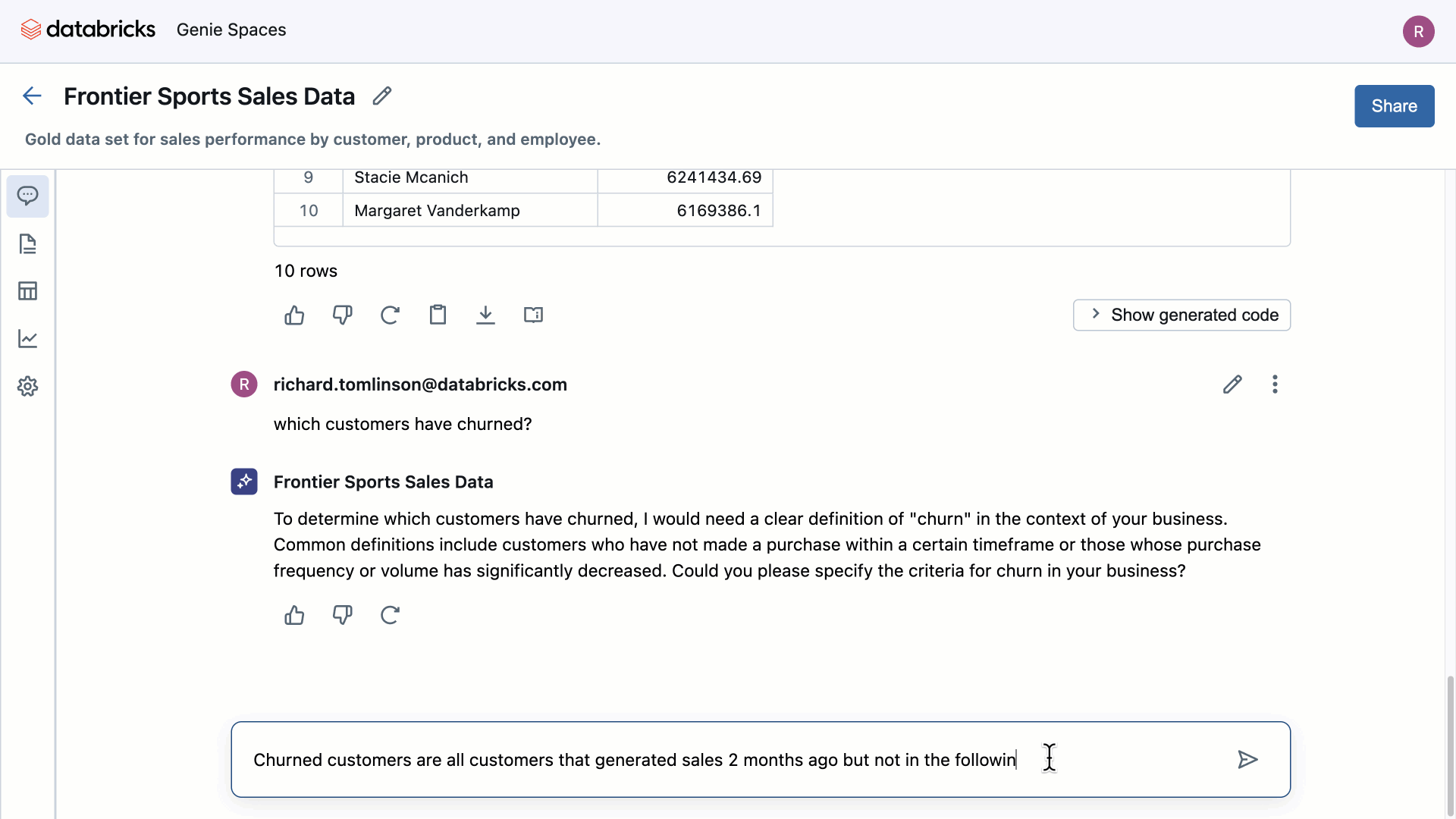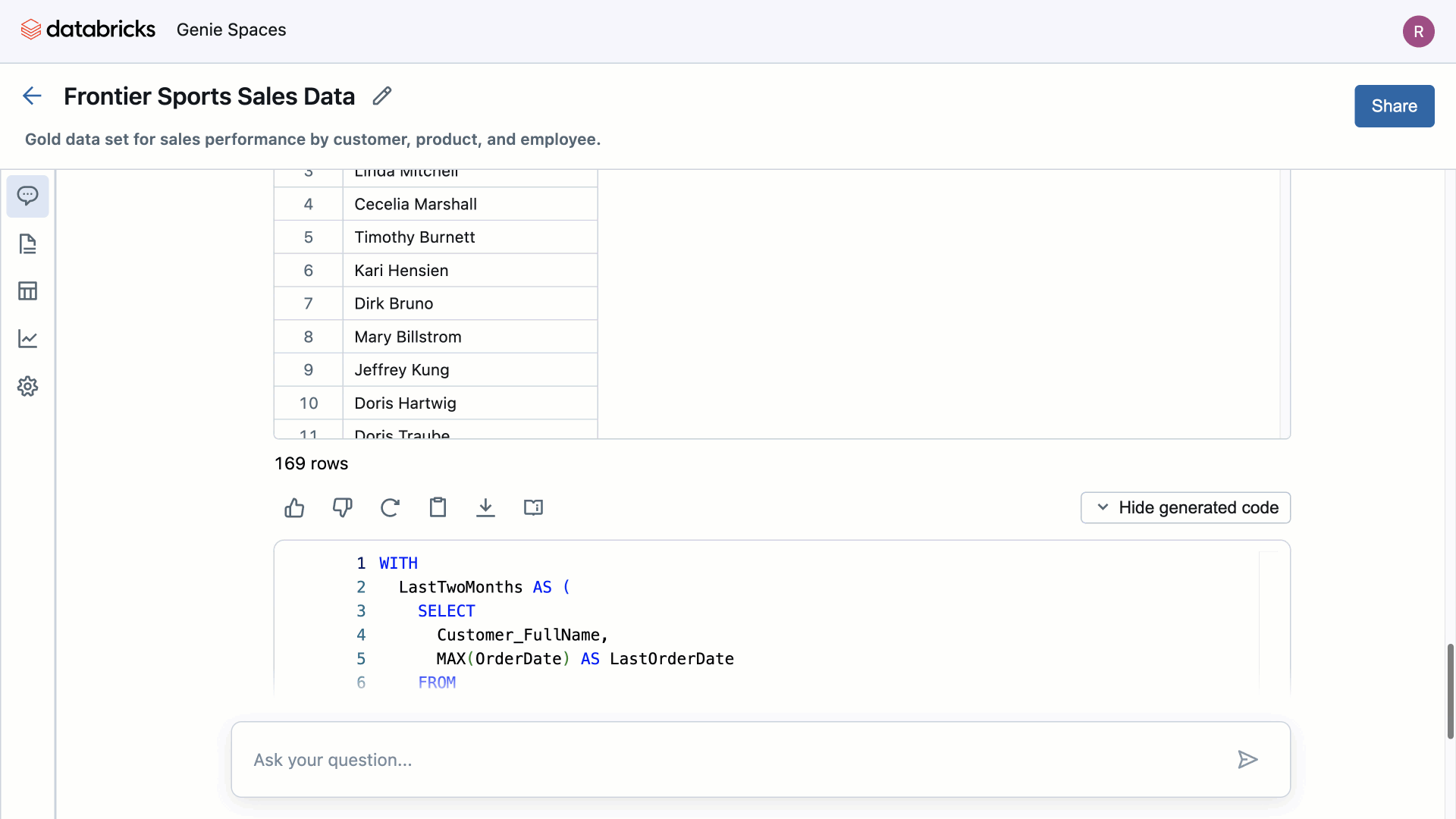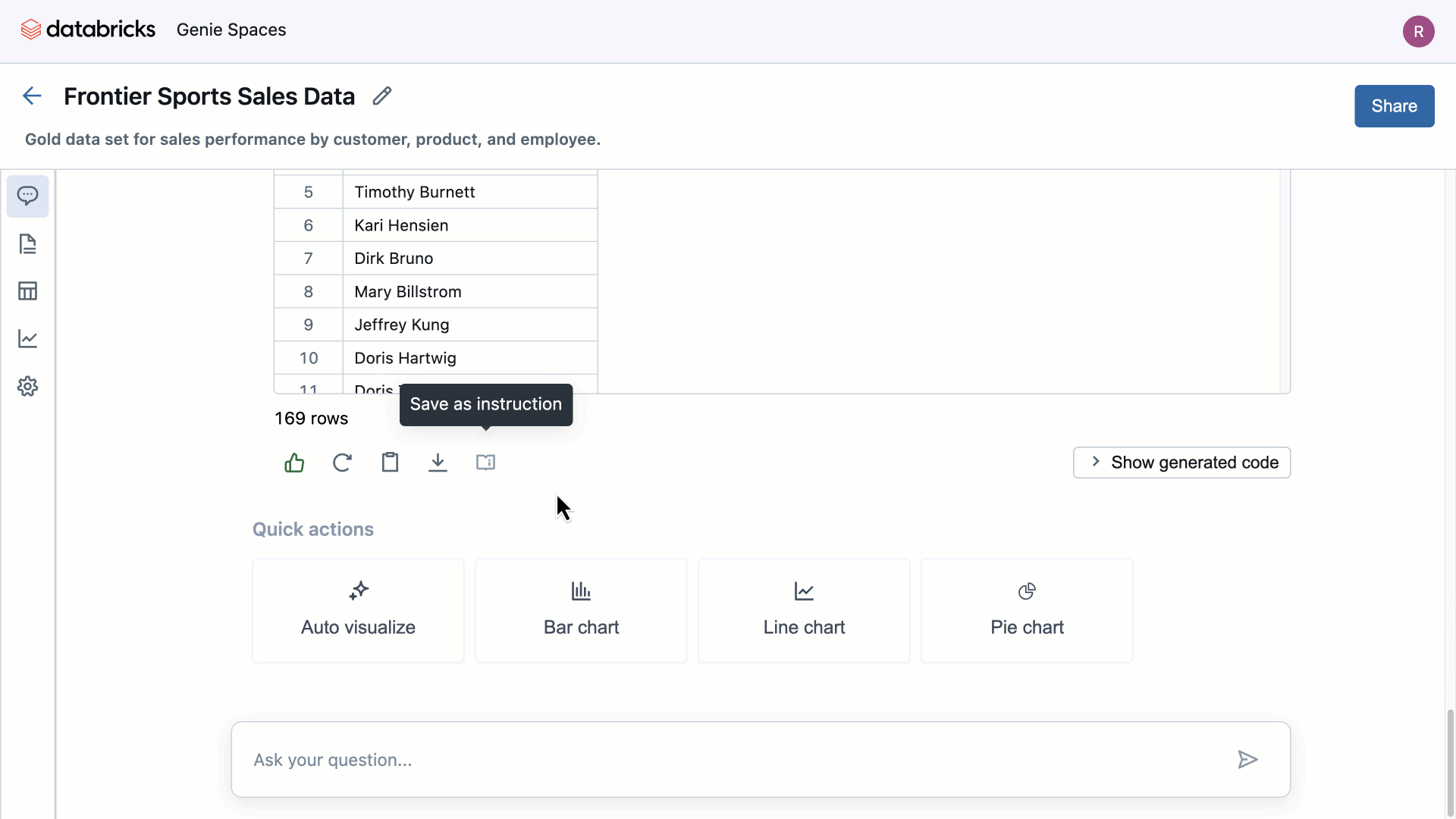
Source: Databricks
During the development of our projects, we found that, on some occasions, the results did not match expectations. This was due to multiple factors: technical aspects (for example, a client with a poorly documented data model or without enriched metadata is likely to encounter issues), a poorly defined scope (the query may require a table not included in the workspace, and Genie only operates on the data we define), or even an inadequate formulation of the question.
For instance, “How has the average balance evolved?” is very different from “How has the average balance evolved over the last 3 months?” Ignoring the “date” or “time period” factor can lead to erroneous results. If we analyze it, an SQL query that aims to average the evolution of balances must consider the temporal dimension, which is completely logical, but when conversing, it is not so evident.
Furthermore, using terms that do not align with a company’s specific nomenclature can generate additional errors. These issues, although they create noise and leave a bad taste, are perfectly solvable and do not represent an insurmountable challenge, provided they are addressed proactively. Prior experience allows us to anticipate and correct these problems, thereby reducing friction with the client.
In conclusion, the key to building a successful AI agent with Databricks Genie lies in the combination of three elements:
An adequate configuration of the agents—which includes defining the correct scope, selecting the pertinent tables, establishing robust governance, and meticulously reviewing tables, fields, and metadata, along with appropriately pre-configured prompts, defined nomenclatures, and well-structured example questions.
Effective user training.
Constant interaction with stakeholders to ensure that the final solution meets their expectations.
With this approach, I have no doubt that users will increasingly “converse” with their data.

Source: SunnyData
Best Practices for Formulating Questions and Onboarding the User
We’d like to share some essential tips based on our experience and interaction with end users so that these initiatives generate as little friction as possible. We are not focused on detailing “every single best practice” (although in the previous section, we briefly mentioned development best practices), but rather on the crucial moment when the end user first engages with the application and how to train them for optimal use.
Tip: Before proceeding with the list, I must make it very clear—and I apologize for being insistent—that under no circumstances should such an application be shared with a user without intensive prior training.
For these initiatives to work correctly, it is essential to thoroughly educate the user, provide everyday examples, and validate that everything operates correctly. Otherwise, if the application is shared “haphazardly,” the user will likely pose queries outside the intended scope, without the necessary logical structure, resulting in inadequate feedback.
Now, let’s move on to some general best practices for the user that we have gathered from the user guides we provide to our clients.
Explain the Scope: Indicate clearly to the user which domains the system has been trained on. This is a good moment to validate whether the tables or sources included are sufficient or if the scope should be broadened due to dependencies (a query might not return accurate results if it requires a table that has not been included and the system does not have access).
Teach How to Formulate Questions: Train the user to structure their queries properly and use the correct terms to achieve the expected results. Some tips include: if you need data for a specific date, include it in the question; for temporal analyses, mention the time period. When a date is not specified in queries that depend on this factor, the results might be erroneous. Additionally, it is important to agree on the terminology used in the system to avoid confusion.
Help Interpret the Answers: Each response comes with the SQL query that was executed in the background. Users with SQL knowledge can validate the correctness of the answer; those who do not can rely on a generative AI to translate and understand the underlying logic, ensuring that the response truly meets their needs.
Question Feedback: Feedback is key to improving Genie’s performance. It is recommended that the user indicate whether the response was helpful (for example, by clicking the “like” icon) or if there was an issue (using the “dislike” icon). They can also provide detailed comments about an error using the question mark icon. This allows for monitoring performance and adjusting the system based on actual needs.

Source: Databricks
5. Interpreting Responses: Typically, the system will respond with tables, just as one would obtain from an SQL query. However, the user can ask Genie to generate a chart based on the query (even integrating it into a custom dashboard, although that topic will be explored in another blog). It is also possible to request additional calculations, such as percentages or averages, to enrich data interpretation.
Conclusions: The Future and Potential of Databricks Genie
In this blog, we have focused on the challenges and lessons learned to optimize both development and the user experience. AI/BI Genie stands out as an exceptional option for building secure and reliable agents. I recommend reading the following Databricks manual (very simple and intuitive) to use Genie correctly: Onboarding your new AI/BI Genie
The capabilities of this service will continue to expand throughout the year, and Databricks will strongly invest in its evolution. We have had the privilege of accessing early features and witnessing firsthand how, in the coming months, Genie will enhance its functionality and transform the way users leverage their data (and we can’t wait to share it with you).
Thanks so much for reading, looking forward to seeing you in the next blog!