PostgreSQL to Databricks Migration: A Simpler Path to the Lakehouse
Today’s post marks the launch of a new structure in our blog: more agile, concise, and to the point.
Why this change? Primarily because, in our previous posts on migrations, we’ve repeatedly explored topics related to project management, planning, coexistence strategies, and similar aspects. Therefore, we will assume these concepts are already clear, given that the only real variable is the source technology (explore our migration blogs here).

In this context, we will specifically discuss migrating PostgreSQL to Databricks. Compared to other alternatives, this migration is relatively straightforward—at least at the beginning. Of course, this simplicity may be challenged when the team faces the task of refactoring 350 stored procedures, but that’s precisely the kind of technical detail we’ll explore today.
Introduction to the Dynamics of Migrations*
*Feel free to skip this section if you’re familiar with it
The conceptual structure of decommissioning follows a common pattern of four macro phases, which can be further divided into secondary stages. However, to grasp the general idea and structure of migrations, we won’t go into detail (we’ve covered that in previous blog posts). The first two phases are more related to the source platform or system being migrated, while the last two depend more on the target technology—in this case, Databricks.
Phase 1: Analysis
The first phase, analysis, focuses on a thorough assessment of the current infrastructure, including data (tables, schemas, number of databases, volume, etc.), functions, stored procedures, and dependencies (both for ingestion and data consumption). This process typically starts in the pre-sales stage and continues through project execution, providing an overview of the migration’s scope and effort. This exercise is not just a detailed technical review but also a comprehensive assessment from a functional and business perspective.
Phase 2: Design
This phase is followed by the design phase, which is highly dependent on the previous one. Poor analysis will lead to a flawed design phase and a disastrous project kickoff. At this stage, the migration strategy (Lift & Shift, Modernize, or Refactor) for each technological component or involved process is defined. This strategy is determined by critical factors such as available time for execution, the source technology (we’ll cover a concrete example in the next blog), and a balanced approach between current and future costs.
For example, building a component from scratch might require a higher initial investment in professional services, but it could also result in lower operational costs and better efficiency in the medium to long term.

Phase 3: Development
Next comes the development phase, when we move away from the source technologies and focus more on adapting to the target platform—in this case, Databricks.
During this phase, the Unity Catalog schema in Databricks will be designed to align with business needs, and PostgreSQL code will be translated to ensure compatibility with Databricks. We’ll explain and illustrate how this process works conceptually in the next section.
Context: RDBMS with Stored Procedures or Procedural Logic
This section applies to the present blog post as well as future publications related to migrations from relational databases that contain stored procedures, procedural logic, or PL/SQL (or similar) support. This includes widely used RDBMS such as PostgreSQL, Oracle Database, Microsoft SQL Server, MySQL, and IBM DB2.
⚠️ Important: Databricks supports all standard ANSI SQL commands. However, PostgreSQL—like other RDBMS—extends the SQL standard with specific functionalities that do not exist in Databricks. For example, the CREATE PROCEDURE statement is not valid in Databricks. - Update: This does not apply anymore. Now it's supported.
So, how can these functionalities be replicated in Databricks?
Procedural SQL code from PostgreSQL can be migrated easily by converting it into Python functions hosted in notebooks. Thanks to Databricks Workflows, it is possible to replicate the original logic and automate these processes, fully leveraging the platform’s integrated programming, scalability, and native orchestration capabilities.
While this is less of an issue today—since most companies have adopted Lakehouse architecture—there was a time when confusion arose around Databricks not supporting stored procedures, leading some companies to choose traditional solutions instead. The truth is that Databricks is incompatible with traditional stored procedures and requires code refactoring, but the result is the same. - Update: This does not apply anymore. Now it's supported.
Yes, it does require extra effort. However, with advancements in AI and code conversion accelerators, even if Databricks supported stored procedures traditionally, it would still be more beneficial to refactor in order to fully capitalize on a cloud-native platform.

Technically, What Does The Migration Involve?
The main challenge is transforming stored procedures into Python functions that can be managed through Databricks Workflows. While several approaches exist, we'll focus on the most straightforward one for teaching purposes.
The first step is getting the database schema. We'll use pg_dump to generate an SQL file with all table definitions and stored procedures. With this file, we can replicate tables in Databricks—making sure to adjust for differences between PostgreSQL and Databricks field types. Since Databricks doesn't support CREATE PROCEDURE statements, we'll need to rewrite the logic to Python (using AI assistance can save a lot of time). - Update: This does not apply anymore. Now it's supported.
Here’s an example:
📌 1. Creating a table in Databricks:
Equivalent to PostgreSQL but adapted to the Databricks metastore.

🐍 Converting a PostgreSQL stored procedure to Databricks using Python:
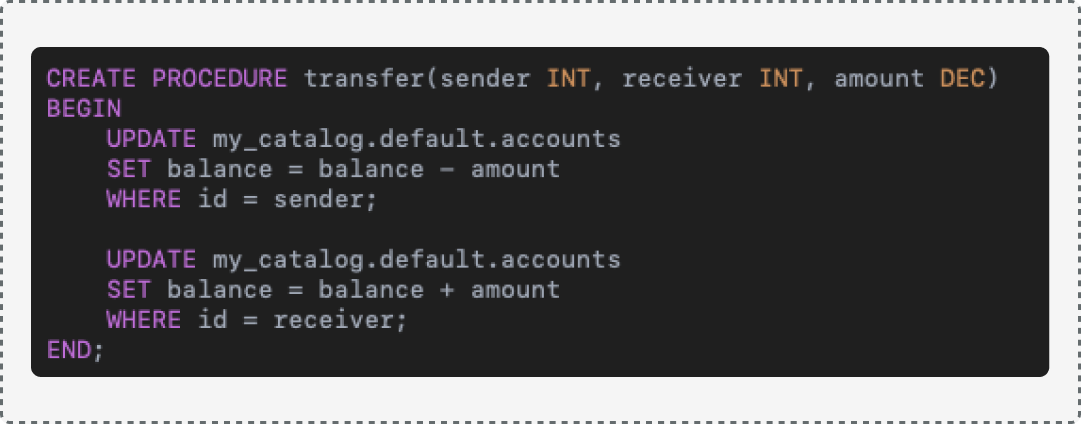
The original PostgreSQL procedure:

👉 Databricks now supports SQL Scripting, so we have two options for implementation: using SQL scripting or using Python for more flexible execution within notebooks.
Python example:

Execute function in a notebook: transfer(1, 2, 2000)
Validate the result with SQL: SELECT * FROM hive_metastore.default.accounts;
This process shows you how to effectively transform your SQL logic for the Databricks platform using Python and notebooks. Your end result should work exactly like the original, and you'll want to thoroughly test to ensure the new Python code behaves the same way as your original PostgreSQL procedures.
Beyond Code Conversion: Other Key Components to Consider
Migrating from PostgreSQL to Databricks is not just about converting stored procedures into Python functions—it also requires restructuring the orchestration layer. This means identifying how and where these procedures are triggered and adapting those workflows within Databricks Workflows or external orchestrators to ensure seamless execution. By redesigning dependencies, triggers, and execution flows, we can align with Databricks’ architecture and optimize data processing pipelines.
For data loading, we use standard ETL/ELT techniques, such as Spark notebooks that read CSV, JSON, or Parquet files, storing everything in Unity Catalog tables within Databricks. Additionally, as part of the validation phase, it’s crucial to test thoroughly to ensure the new Python-based implementation behaves exactly like the original PostgreSQL procedures. Data quality accelerators in Databricks can help automate this validation process, ensuring consistency and accuracy across datasets.
Another critical step is repointing data consumers to the migrated platform. This includes BI tools (e.g., Power BI, Tableau) and ML pipelines, which must be reconfigured to query from the new Databricks environment instead of PostgreSQL. Ensuring a smooth transition for these consumers is essential to minimize disruption and maintain business continuity.
🔥Update (March 2025): Impact of SQL Scripting in Databricks SQL Scripting
The availability of SQL Scripting in Databricks significantly changes the approach for migrations from traditional RDBMS. Previously, Databricks did not support native stored procedures, requiring logic to be rewritten in notebooks.
With this update, we can now write SQL scripts and stored procedures directly in Databricks, reducing the need for code adaptation and enabling a migration approach closer to Lift & Shift.
How does this affect PostgreSQL migrations?
Less conversion to Python: No longer necessary to transform stored procedures into Python functions, simplifying the migration of advanced SQL logic.
Databricks SQL Scripting Example (hypothetical based on the same exercise)
Native compatibility with traditional databases: Full SQL scripts can now be written directly in Databricks, reducing friction for teams used to working with PL/pgSQL.
Optimized query execution and ETL/ELT processes: Complex SQL workflows can be designed, scheduled, and executed within Databricks, eliminating the need for notebooks.
Improved governance and auditing: By allowing stored procedures and SQL scripting, it facilitates the standardization of queries and processes in enterprise environments.
Final Reflection: Which Option is Better?
Now that we have both options, which one is the best? In my opinion, converting code to Notebooks remains the recommended approach, as it provides greater flexibility, scalability, and integration with Databricks workflows.
However, SQL Scripting is a valuable alternative for clients with a strong dependency on stored procedures. It allows for a smoother transition, reducing migration effort and maintaining existing logic when time constraints or operational continuity are priorities.
Ultimately, the best choice depends on the organization’s needs, technical strategy, and long-term goals.
Deployment Phase (And Decommissioning?)
Before going all-in, it's best to start with a small pilot group of users or a limited dataset to validate the migration. This approach helps both you and your client reduce risk and uncertainty.
The process should follow an iterative cycle:
Migrate one module/domain at a time, test it thoroughly, and get feedback.
Make any needed adjustments to your code or settings.
Repeat until you've completely moved all PostgreSQL code and data to Databricks.
Now, what happens once everything is migrated and validated?
It’s time to decommission or dismantle the old technology. This phase is often overlooked 🤷♂️, leading to technical debt in many organizations.
To maximize Return on Investment (ROI), it’s essential to:
✔️ Plan the retirement of legacy PostgreSQL systems.
✔️ Deactivate old servers, databases, and connections.
✔️ Redirect all processes and applications to Databricks.
Conclusions
As we've shown, moving from traditional data warehouses like PostgreSQL to Databricks is fairly straightforward in concept—but that doesn't make it simple in practice. Many enterprise clients have built up years of stored procedures (often with little to no documentation) that can be incredibly complex, giving engineering teams their work cut out for them.
That's why it makes sense to use acceleration tools like BladeBridge or SunnyData's custom accelerator to speed up and simplify the whole process.