Seamless Data Integration: SAP to Databricks

SAP is a company that offers various enterprise resource planning (ERP) software and data management technologies (MDM, ETL, Analytics, BI) to complement its core ERP solutions for areas such as sales, logistics, finance, human resources, and more. Its products have also evolved, developing new generations and adapting through cloud-based solutions. Why is it important to understand SAP before getting started? As you can imagine, this universe of products that generate and store data is enormous, and each product or service in SAP’s portfolio has its own particular nuances.
In fact, without knowledge of these details, we will likely encounter problems as we move forward with the project. These details could make the difference between implementing it one way, another, or even not being able to carry it out at all—due, for example, to missing licenses or configurations in the source system. For this reason, we suggest involving professionals well-versed in the SAP ecosystem. Their expertise helps ensure all the foundational elements are in place, streamlining the initial setup and safeguarding both the project’s direction and its final results.
Introduction to the SAP Ecosystem for Databricks Integration
To provide the reader with a clear overview of SAP’s main products, we have organized the information as follows (it’s important to note that this is not an exhaustive list, but it includes products we will likely encounter in our projects):
Data from the internal SAP ecosystem: These are the data generated by SAP products primarily designed for business operations purposes, such as planning, marketing, human resources, among others.
In the realm of ERP systems, the most notable are SAP ECC, SAP S/4HANA, and SAP Business One:
SAP ECC: This is the classic version of SAP’s ERP systems, widely used and considered the predecessor of SAP S/4HANA. SAP has made significant efforts to facilitate the transition to the new generation.
SAP S/4HANA: This represents the new generation of ERP, designed to leverage the capabilities of the in-memory SAP HANA database. It offers real-time analytics, cloud optimization, and greater operational efficiency.
SAP Business One: This ERP is specifically designed for small and medium-sized businesses. It has limitations in handling large volumes of data, advanced functionality, fewer integration options, among others.
The ERP section is the most relevant and the one you will most frequently encounter in projects. In addition, we have mentioned other SAP products designed for different purposes, which are also widely used. They integrate natively with some of the aforementioned systems (mainly S/4HANA) and may also appear in your work.
SAP SuccessFactors: A comprehensive solution for talent and human resources management, designed to enhance the employee experience throughout the entire work lifecycle, from recruitment to retirement. It integrates with SAP S/4HANA to connect HR data with finance and operations.
SAP Marketing Cloud: A platform designed to execute personalized, data-driven marketing campaigns in real-time. It enables dynamic audience segmentation, omnichannel campaign creation, and customer behavior analysis. It works natively with SAP Commerce Cloud to unify marketing and e-commerce data, and with SAP Customer Data Cloud to securely manage customer data and consent.
SAP Commerce Cloud: A solution for creating and managing omnichannel e-commerce experiences, supporting complex catalogs, multiple languages, and currencies. It connects with SAP Marketing Cloud to leverage campaign data and personalize online shopping experiences. It also integrates with SAP S/4HANA to manage inventories, pricing, and financial processes related to e-commerce.
SAP IBP: An advanced tool for collaborative, real-time supply chain planning. It includes modules for demand, supply, inventory, and sales planning, optimizing operations through simulations and predictive analytics. It works closely with SAP S/4HANA to ensure that financial, operational, and logistical data remain aligned.
2. SAP Data Ecosystem: Given the vast amount of data generated by its ecosystem, SAP has developed specific solutions to integrate, manage, and leverage this data. For those who are new to this area, the product portfolio can seem overly complex or disorganized.
To simplify understanding, we propose dividing this ecosystem into three categories and one integrative or central foundational block. We will use the diagram below to understand the SAP Data Ecosystem.

First, we have SAP Business Technology Platform (SAP BTP), which serves as the central technological foundation of the SAP ecosystem. This platform supports key solutions such as SAP Analytics Cloud and SAP Datasphere, including underlying components like SAP HANA. SAP BTP functions as an enabling technology layer that connects applications, services, and data, allowing for seamless integration and optimizing the use of tools within the SAP ecosystem.
Within SAP BTP, we find SAP Analytics Cloud (SAC) – an Analytics Tool – and SAP Datasphere – a Data Management and Modeling Module.
SAP Analytics Cloud (SAC): This is SAP’s business intelligence and analytics tool, designed to integrate planning, visualization, and predictive analysis into a single platform. SAC connects directly with SAP Datasphere, SAP HANA, and other data systems, providing a unified experience for exploring and leveraging business information.
SAP Datasphere: This is the advanced data management solution within SAP BTP. It enables connecting, federating, and modeling data from multiple sources, both from the SAP ecosystem and external environments. Datasphere is the enhanced successor to SAP Data Warehouse Cloud, offering greater integration capabilities and a focus on data federation for simplified and centralized access.
SAP Data Warehouse Cloud (DWC): This is a data storage and analysis solution designed to combine and manage structured and unstructured data from various sources. While still relevant, DWC has evolved into SAP Datasphere, which expands its functionalities with a more modern and flexible approach to enterprise data management.
This category focuses on data storage and data warehousing technologies within the SAP ecosystem, with SAP HANA standing out as the primary engine.
SAP HANA: This is the in-memory database that supports both transactional and analytical systems. It is the underlying engine of many SAP solutions, including SAP BTP, SAP Analytics Cloud, and SAP Datasphere. HANA provides real-time processing, making it ideal for applications that require speed and instantaneous analysis of large data volumes.
SAP BW/4HANA: A data storage and analysis solution. This is the most recent version, fully redesigned to work on SAP HANA. It offers more agile modeling and advanced data integration capabilities. It integrates better with modern solutions such as SAP Analytics Cloud and Datasphere.
SAP BW: Designed to run on standard relational databases like Oracle or SQL Server, using a traditional data warehousing approach.
SAP BW on HANA: With the introduction of SAP HANA, SAP BW was optimized to leverage the speed and in-memory processing capabilities of HANA. This enabled real-time analytics and dramatically improved performance.
With this introduction, readers now have an initial overview—quite enriching for a blog—of SAP’s main components, their functionalities, and how they relate to each other. This will help them better understand what they will face in the SAP ecosystem in terms of technologies and their purpose in the business environment.
How to ingest data from SAP into Databricks
The purpose of this article is not to ‘confiscate’ or replace any SAP component, but rather to work together. As we saw in the previous section, although SAP has products designed for data management and storage, it does not directly compete with Databricks. Likewise, Databricks cannot replace the vast functionality that SAP offers its users in terms of planning, operations, and business processes.
That said, we will now explain some alternatives for ingesting data from certain SAP components into Databricks in order to take advantage of the best of both worlds: Databricks’ advanced analytics capabilities and focus on big data, combined with SAP’s strength in enterprise management. Let’s get to it!
SAP HANA (Option 1: SparkJDBC)
There are multiple methods to federate tables, SQL views, and calculation views from SAP HANA into Databricks. To integrate Databricks with SAP HANA and access its data in real-time, it is recommended to use the SparkJDBC connector. This method allows you to establish parallel JDBC connections from Spark worker nodes to the SAP HANA endpoint, enabling efficient and scalable integration.

Below are the steps to achieve this integration:
Configure a Databricks cluster that has access to the SAP HANA instance. Make sure you are using an All-Purpose (Classic) cluster for compatibility with the JDBC configuration steps below.
Configure the SAP HANA JDBC driver:
a > Obtain the ngdbc.jar file, which is the SAP HANA JDBC driver.
b > Install in Databricks:
Access the cluster management interface in Databricks.
Select the desired All-Purpose (Classic) cluster and go to the “Libraries” tab.
Click on “Install New” and select “DBFS” as the library source and “JAR” as the type.
Upload the ngdbc.jar file from your local system.
3. Establish the connection from Databricksa > Define the connection parameters:
Driver: com.sap.db.jdbc.Driver
JDBC URL: jdbc:sap://<SAP_HANA_Host>:<Port>
Credentials: A username and password with appropriate permissions in SAP HANA.
b > Create the connection in Databricks:
Use the following code in a Databricks notebook to read data from SAP HANA:

Replace <SAP_HANA_Host>, <Port>, <Username>, <Password>, and <Table_or_View_Name> with the appropriate values for your environment.
4. Licensing: You must have a SAP HANA Enterprise Edition license to enable this type of integration.
Data Ingestion to Azure (Option 2: ADF/Azure Synapse)
Azure Data Factory (ADF) and Azure Synapse Analytics offer a variety of native connectors to extract data from SAP systems, adapting to different integration scenarios. Below are the main connectors available, though we will primarily focus on the last one, which in our view is the most suitable:

SAP ECC Connector: Allows extracting data from SAP ECC through OData services, requiring the installation of SAP Gateway. Considerations: Not ideal for massive extractions due to low performance and lacks support for incremental loads.
SAP Table Connector: Enables direct extraction of tables from SAP ECC using RFC connections. Requirements: Appropriate SAP licensing is needed. Recommended Use: Suitable for tables with manageable data volumes that allow full loads, such as master data tables.
SAP Business Warehouse (Open Hub) Connector: Extracts data from SAP BW using Open Hub objects, which enable exporting data to external files or tables. Requirements: Specific licensing is required. Considerations: Recommended for non-incremental extractions.
SAP Business Warehouse vía MDX Connector: Enables the extraction of data from cubes and BEx queries in SAP BW using MDX queries. Considerations: Not recommended due to low performance, MDX restrictions, and lack of support for incremental loads.
SAP HANA Connector: Facilitates copying data from SAP HANA databases, including information models such as analytic and calculation views, as well as row- or column-based tables. Compatibility: Supports any SAP HANA version. Considerations: Requires the installation of the SAP HANA ODBC driver on the self-hosted integration runtime environment.
SAP Cloud for Customer Connector: Allows copying data from SAP Cloud for Customer to compatible data stores or vice versa, facilitating data integration between cloud-based and on-premises systems. Considerations: Requires proper configuration of SAP Cloud for Customer APIs and may need a self-hosted integration runtime environment depending on the data location.
SAP Change Data Capture (CDC) Connector: Uses the SAP Operational Data Provisioning (ODP) framework to perform incremental loads of transactional data and some master data.
Advantages: This is the recommended connector for data extractions in SAP ECC and SAP BW/BPC, as it automatically captures and merges incremental changes into a consistent target data store, eliminating the need for full extractions and providing near real-time data integration.
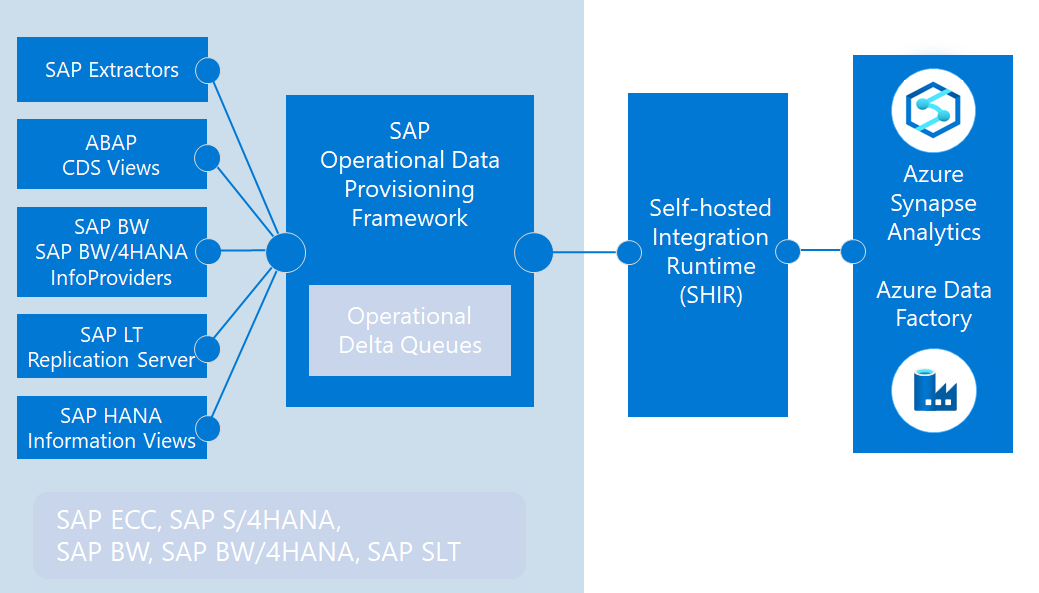
The SAP CDC connector utilizes the ODP framework to enable efficient and advanced data extraction. This approach allows the integration of data both from the database level—through HANA tables and views—and from the application server, using SAP extractors, Core Data Services (CDS) views, and SAP BW objects. Additionally, by using the SAP LT Replication Server (SLT), it’s possible to replicate tables in real-time, providing near-instant analytical capabilities and synchronization of transactional data.
Among the main advantages of the ODP framework is its ability to perform incremental (delta) loads when working with SAP extractors, CDS views, and SLT-managed tables. This minimizes the volume of transferred data and optimizes integration processes. Moreover, ODP allows the reuse of the same data sources for different targets, simplifying the integration architecture and reducing redundancy.
To integrate SAP ECC using the SAP CDC connector, certain technical prerequisites must be met:
Configuration of ODP API 2.0 in SAP ECC: Ensure that the PI_BASIS component is at version 740 SP04 or higher. This guarantees the availability of the ODP framework required for data extraction.
Installation of the DMIS component: The DMIS 2011 component should be at version SP05 or higher. However, it is recommended to use DMIS 2011 SP15 or a newer version to ensure compatibility with DMIS 2018.
Implementation of a dedicated SLT server: For efficient replication, it is advisable to have a separate SAP Landscape Transformation (SLT) server acting as a central server. This server should run DMIS 2018 SP05 on NetWeaver 7.5+, allowing the installation of SLT version 3.0. Having one SLT server per SAP ECC environment is recommended.
Configuration of system connections: Establish robust connections between the SAP ECC environments and their corresponding SLT systems. Additionally, configure communication between the SLT systems and Azure Data Factory via the SAP CDC connector, ensuring smooth and secure data transfer.
Meeting these prerequisites is critical to ensuring effective and trouble-free integration between SAP ECC and Azure Data Factory, optimizing extraction and loading processes so that data can then be leveraged in Databricks.

Conclusions
We hope this blog has been helpful, especially for those who are just starting a project or conducting preliminary research to ensure a well-executed outcome. My final recommendation is to dive deeper into all the available documentation from SAP, Azure, and Databricks, taking advantage of the resources offered by their respective communities and official guides.
Additionally, make sure to gather all relevant information in advance about modules, versions, licenses, and other technical details of the SAP environment to avoid potential blockers or setbacks during the project’s implementation.
Good luck with your projects, and we’ll see you in the next blog next week!