What is Photon in Databricks and, Why should you use it?
Introduction
Photon is a native vectorized engine developed in C++ to dramatically improve query performance. It seamlessly coordinates work and resources, transparently accelerating portions of your SQL and Spark queries. Photon's focus is on executing SQL workloads faster, ultimately reducing your total cost per workload … Well, I think we're moving too fast. Let's try to understand everything thoroughly. I promise that by the end of this blog, you'll fully grasp why Photon is a significant milestone in Databricks.
To comprehend Photon, understanding Spark fundamentals is crucial before delving into practical applications. With this goal in mind, we will start this blog by discussing Spark. Afterward, we will provide a brief overview of programming languages to grasp the technical reasons behind certain choices. Finally, we will circle back to Photon, exploring what it is, its benefits, and examining some performance benchmarks.
Challenges Addresses By Spark
The need for Spark arises due to growing data complexity and the inefficiency of using a single machine. Unlike the ideal scenario of very well organized data in a data warehouse, real-world data comes in various formats, with unpredictable column types and potentially high null values. Dealing with such complex and fast-paced data becomes impractical on a single, machine.
To address the challenges posed by growing and complex data, Spark leverages the power of parallel processing. Simply scaling up a single machine is not cost-effective, and the odds of utilizing it at full capacity are slim. Big data benefits from parallel execution, necessitating the use of smaller machines grouped together for more efficient processing.
How Parallel Execution Works in Apache Spark
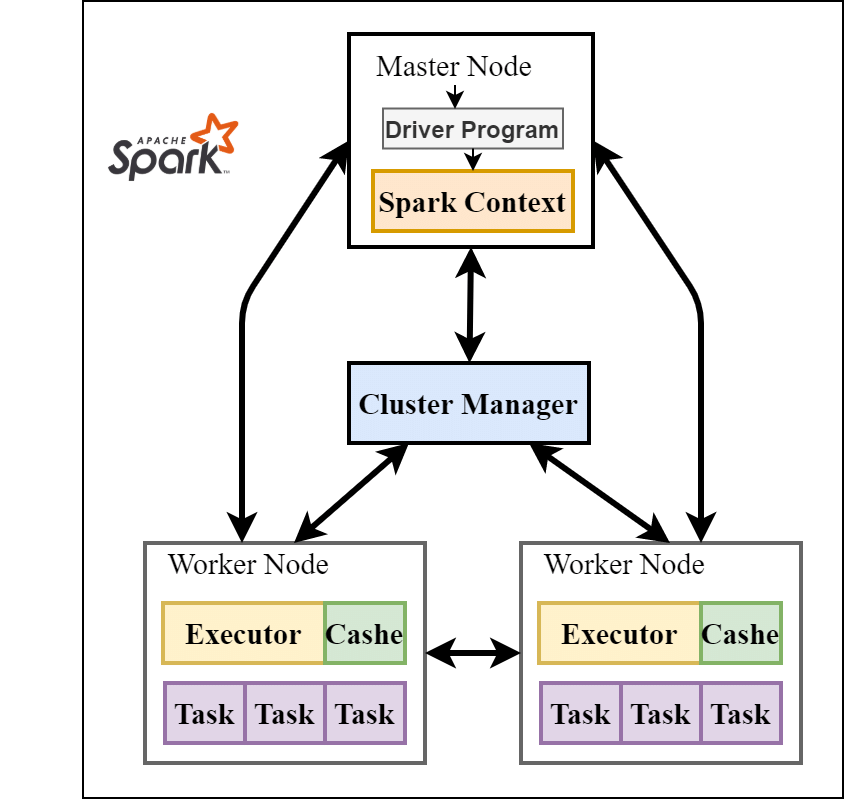
In a Spark cluster, one node acts as the Driver, responsible for coordinating the overall job. The rest of the nodes are Workers, which carry out the tasks assigned to them. The driver breaks down your code into a plan and uses this plan to distribute tasks to the workers. If a worker fails, the driver can reassign its tasks to another worker.
Spark divides your data into partitions. These partitions can be distributed across the workers in your cluster. This allows multiple workers to process different parts of your data in parallel, leading to faster overall execution times.
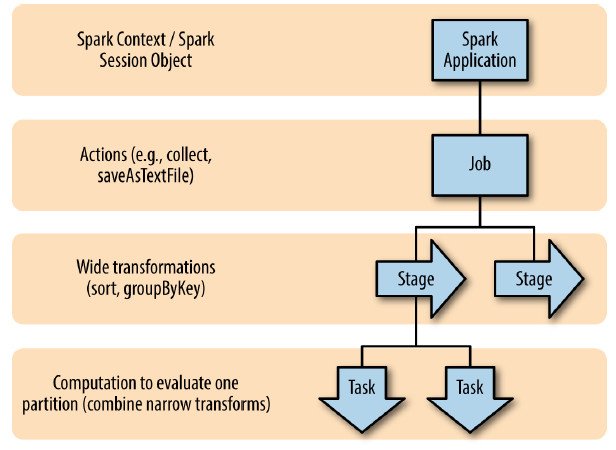
Spark's data processing breakdown forms a hierarchy:
Actions: User code triggers actions which launch computations
Jobs: Actions break down into a series of job
Stages: Jobs are composed of stages bounded by data shuffles
Tasks: Stages break down into tasks, the atomic unit of work carried out on a worker processing a single partition.
The pivotal question is how Spark determines which data goes where and which operations to perform. In this context, the Catalyst Optimizer comes into play. It analyzes your code, identifies logical efficiencies, and ultimately constructs the physical execution plan that determines how your data will be processed.

Once the physical plan is established, Spark transitions into a code generation phase to enable the execution of those optimized instructions. In Spark, DataFrames offer a structured representation of data accompanied by descriptive metadata. The logical plan formed earlier undergoes validation and optimization before being translated into code. This code generation step involves taking optimized rules from the plan and transforming them into RDDs (Resilient Distributed Datasets) ready for execution.
Spark Programming Language Backbone
Our journey begins in 1979 with C++, a language born from the roots of C, which emerged in 1972. C++ boasts raw speed as it compiles directly into machine code, the language of computers. Yet, its complexity lies in the demand for a deep understanding of memory management, making it less user-friendly for general tasks. And yes, it's not the language of Spark, but it's important to mention because we will revisit C++ when discussing Photon (remember, Photon is developed in C++).
Hardware: The Physical Foundation
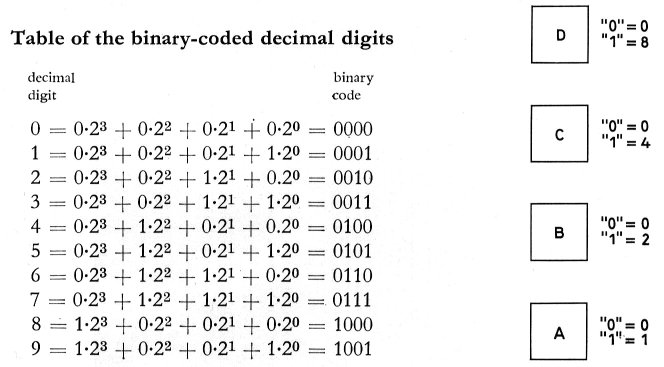
The essence of hardware lies in the binary realm of ones and zeros. This binary representation is the language of computers, where numbers are sculpted into sequences like 0111 to represent seven. Handling this binary landscape involves defining memory size and assigning addresses – a crucial facet mastered by skilled C++ programmers.
Character Encoding: From Bits to Letters
But how do we communicate in letters and words? ASCII steps in, a standard encoding where eight bits, like 01100001, embody the lowercase 'a'. While ASCII grants us 128 characters, it falters when dealing with languages featuring accented characters or diverse symbols, demanding more memory.

Evolution of Languages: Java & Scala
In the early '90s, a revolutionary shift occurred with the introduction of Java. Departing from the trajectory of C++, Java adopted a distinctive approach by compiling not into machine code but into "bytecode," a universal language interpreted by the Java Virtual Machine (JVM). The JVM emerged as a versatile translator, liberating programmers from the intricacies of manual memory management, albeit at the expense of some speed.
Scala made its debut in 2004, entering the scene alongside Java and seamlessly operating on the JVM. By 2011, it had gained commercial significance, perfectly aligning with the emergence of Spark in 2014. Scala set itself apart with its concise code, support for functional programming, and adept memory management tailored for data-intensive applications, solidifying its role as the virtuoso for parallel data manipulation.
Memory Management and Data Processing
As our focus transitions to the critical role of memory, the spotlight intensifies. The act of writing to memory, executed with the finesse of a swift maestro, surpasses the lethargy of disk storage, making it the ideal repository for intermediate results. However, a cautionary note arises—memory saturation initiates a domino effect: processes decelerate, garbage collection becomes a frequent visitor, and the imminent risk of losing invaluable data looms large.

In this intricate dance between memory and data, the stage is set for our exploration of Spark and the revolutionary advent of Photon.
Vectorization and Spark Metrics
When contemplating vectorization, diverse interpretations of what a vector truly entails and its practical applications may arise. In the case of SIMD (Single Instruction, Multiple Data), it signifies an enhanced integration with the hardware. Within Spark, CPU-level SIMD optimizations are employed, enabling compatible operations to be executed in parallel. This form of vectorization was incorporated into Spark around version 2.0.
The crux of SIMD lies in its capability to process multiple sets of data simultaneously, leveraging memory parallelism and delivering substantial benefits. It's crucial to note that, although this concept may seem oversimplified, in reality, it is far from trivial. Successful implementation requires not only the right hardware but also specialized knowledge, and even then, achieving 100% coverage across all query types is unattainable. SIMD vectorization, therefore, represents an advanced approach that demands a precise blend of resources and technical expertise to unleash its full potential in environments such as Spark.

The challenge next came with vectorized user-defined functions (UDFs) in Spark. These UDFs involve custom logic not covered by Spark, leveraging Apache Arrow to enhance data organization in memory and reduce unnecessary data movement. A crucial feature is their batch-level operation, introduced to Spark in 2017, marking a significant advancement.
In the broader context of vectorization, the trend is clear. Vectorization in Spark means processing data in batches, specifically homogenous columns, eliminating the need for mixing and matching. This shift towards optimized and efficient data processing represents a fundamental change in Spark's approach.
Spark's popularity doesn't necessarily equate to perfection.
Over its nearly 10-year existence, there has been a relentless pursuit of performance improvements. Efforts ranged from optimizing hardware to tackling challenges like SIMD (Single Instruction Multiple Data) integration, a complex task requiring in-depth knowledge.
Caching strategies were explored, involving storing intermediate results in memory to enhance efficiency. Catalyst Optimizer received enhancements, such as the adoption of adaptive query execution, which involves feeding back statistics during job execution for better data partitioning decisions.
Delta, a widely used storage layer, played a crucial role in optimizing file size and data layout for faster scanning. Despite impressive speed improvements, certain design choices, like JVM-related challenges and a row-based setup, presented hurdles. Row-based structures clashed with the efficiency of columnar data formats used by SIMD and other technologies.
Debugging code generation complexities also emerged as a challenge. While Spark is integral to data engineering, areas like JVM optimization and code generation proved intricate. In summary, Spark is indispensable in data engineering, operating at the task level through Catalyst Optimizer, executing Scala code on the JVM. Despite significant performance gains, the journey continues, as the pursuit of speed in the data landscape is never truly complete.
Enter to Photon Revolution
Photon, the vectorized query engine from Databricks, introduces strategic changes to dramatically enhance Spark's performance. Initially, it transitions performance-critical code from Scala to faster C++, resulting in a cleaner and more efficient code generation process. Photon is carefully designed to only employ C++ where it offers the most significant gains, maintaining full compatibility with your existing Spark ecosystem.
Photon doesn't replace Spark entirely. Instead, it works incrementally, allowing you to see immediate benefits without disruptive code refactoring. Logical and physical query planning remain within Spark, while Photon selectively steps in for the final execution phase, applying its optimizations when specific patterns are detected. This seamless integration between Spark and Photon relies on the Java Native Interface (JNI).

At the heart of Photon's speed improvements are its specialized code kernels. These pre-compiled kernels are meticulously designed to process columnar data in batches (vectorization), handle null values intelligently, and even optimize operations when working with ASCII-only data. Moreover, Photon creates kernels tailored to specific data types, ensuring maximum efficiency.
Photon brings a noticeable transformation to queries that involve searching for data across distributed workers. Its hash join method uses in-memory hash tables for ultra-fast lookups. This eliminates the repetitive and expensive sorting required by traditional join techniques.
While Photon delivers substantial performance gains, Databricks employs rigorous testing to ensure consistent results between Photon and Spark. Unit tests, end-to-end tests, and fuzz tests continuously verify behavior, taking into account any minor output format differences.
Photon: A Quantum Leap in Databricks Performance

Databricks has a history of steady performance improvements, as shown in the Power Test chart from the TPC-DS benchmark. Each iteration brings welcome gains in speed and efficiency. But the latest innovation, Photon, is something truly special.
Photon Blazes Ahead of Previous Runtimes
The chart speaks volumes; Photon doesn't merely offer marginal improvements – it outshines the performance of previous runtimes. Databricks Runtime 8.0? Photon outperforms it by up to a factor of 2x. This isn't just an upgrade; it's a breakthrough.
Real-World Performance: While the technical optimizations are intriguing, evaluating performance in the context of actual workloads is crucial. Photon's most significant impact is anticipated on queries involving heavy joins, aggregations, filtering, and columnar computations.
Real-World Consideration: Databricks uses comprehensive testing to ensure consistency between Spark and Photon even though they use different languages.
Photon shines in these scenarios:
SQL-based Jobs: Accelerate large-scale production jobs on SQL and Spark DataFrames.
IoT Use Cases: Photon enables faster time-series analysis compared to Spark and traditional Databricks Runtime.
Data Privacy and Compliance: Querying petabytes-scale datasets for identifying and deleting records without data duplication with Delta Lake, production jobs, and Photon.
Loading Data into Delta and Parquet: Photon's vectorized I/O accelerates data loads for Delta and Parquet tables, reducing overall runtime and costs of Data Engineering jobs.
Photon offers significant performance advantages for Databricks users in several ways:
Default Enhancement on Databricks SQL: Instantly experience Photon's speed improvements on Databricks SQL without any additional cost or code changes.
High-Performance Runtime Option: For workloads demanding the absolute maximum performance, Databricks offers a dedicated Photon runtime. While this option has a different DBU consumption model, it unlocks even greater processing power.
Seamless Integration: In either scenario, you don't need to modify your existing SQL or DataFrame code. Simply enable Photon in your cluster configuration, and Databricks intelligently applies it for eligible.

Final Conclusion
Photon represents a significant leap forward in processing efficiency for Databricks users. Its C++ foundation provides a major performance boost. Remember, Photon complements Spark, extending its capabilities for even faster results.
Photon is under continuous development, so keep an eye on Databricks releases for exciting new features. If you haven't tried it yet, enable Photon and experience the speed difference first-hand! Stay tuned for our weekly insights, and thank you for being part of our knowledge-sharing community. See you next week!