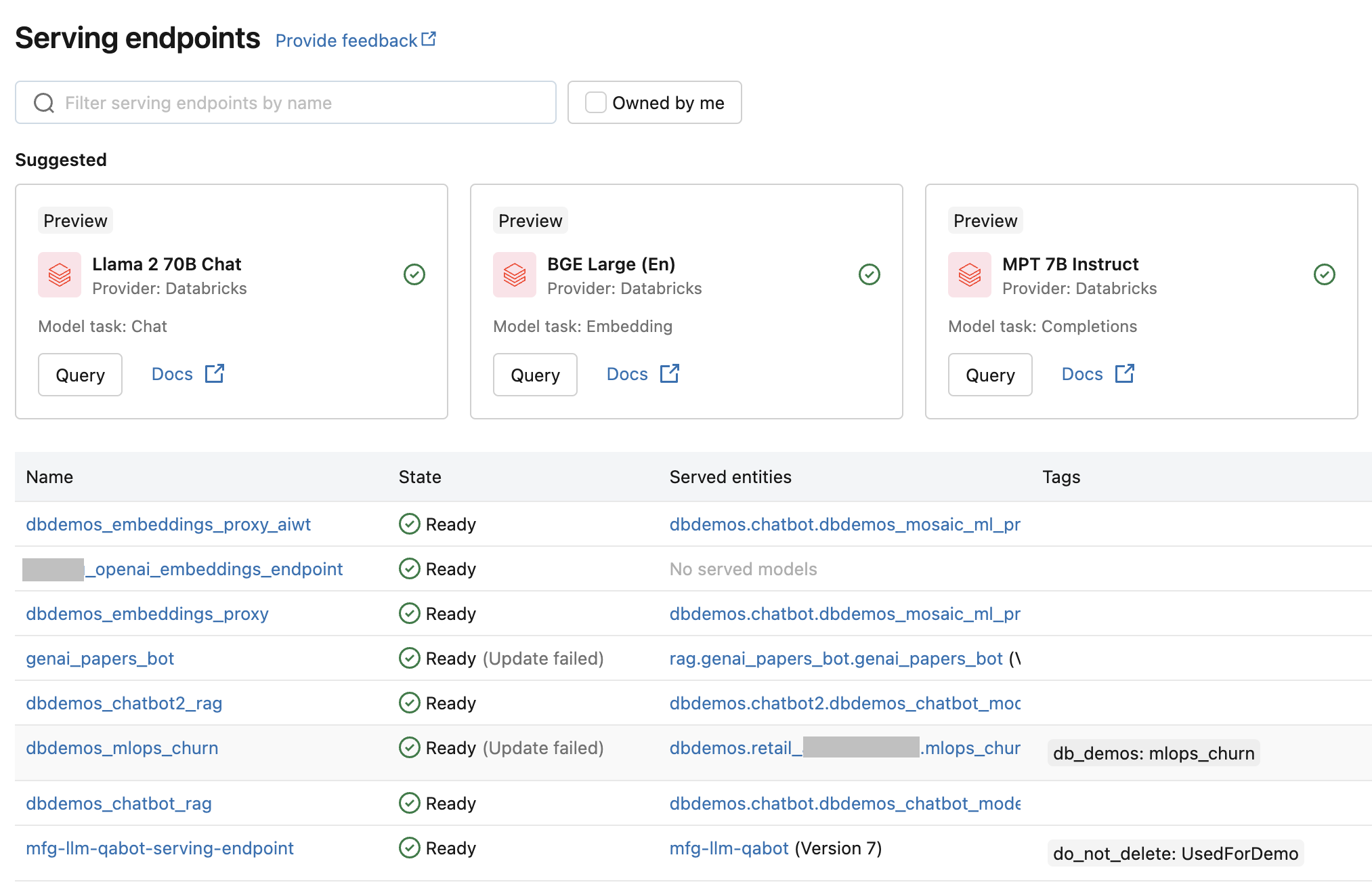
Databricks Model Serving for end-to-end AI life-cycle management
Introduction
In the dynamic realm of artificial intelligence (AI) and machine learning (ML), enterprises seek effective and secure methods for deploying, managing, and scaling AI models. Databricks Model Serving provides a unified platform that simplifies these processes for both in-house developed and external models, emphasizing security, efficiency, and seamless integration.
This service offers a robust, low-latency framework for model deployment through a REST API, facilitating easy integration into web or client applications. It dynamically adjusts scaling to meet demand, leveraging serverless computing to reduce infrastructure expenses and enhance latency efficiency.
Optimize Your Costs and Response Times with Enhanced LLM Serving

Enhanced LLM Serving has significantly upgraded Databricks Model Serving, offering up to a 3-5x reduction in both latency and operational costs for deploying large language models (LLMs). This process is streamlined, allowing for the easy integration of LLMs into your applications without the need for complex optimization code.
Databricks supports deployment on both CPUs and GPUs, automating containerization and infrastructure management. This leads to decreased maintenance expenses and faster deployment times, enabling a more efficient development cycle from idea to production.
To guarantee access to the latest and most accurate information regarding the costs of utilizing Model Serving, we strongly encourage visiting the link below. Here, you'll find detailed and up-to-date insights into pricing structures, available options, and potential costs, ensuring you can make well-informed decisions tailored to your specific needs at Databricks Official Link.
Databricks Model serving allow you the deployment of:
Foundation Model APIs: Grant you access to leading-edge generative AI models, facilitating their seamless integration into applications and eliminating the complexities of model deployment.
Custom Models: These encompass Python-based models packaged according to the MLflow format. Such models can be cataloged within Unity Catalog or the workspace's model registry, covering a range of frameworks including scikit-learn, XGBoost, PyTorch, and models from Hugging Face's transformer library.
External Models: Models hosted externally to Databricks, like GPT-4, also fall under this service's umbrella. It allows for the centralized governance of endpoints serving these models, with capabilities to set access controls and rate limits.
Instant Access to Foundation Models
Databricks Model Serving eliminates the complexities of hosting and deploying foundation models through its Foundation Model APIs. These APIs provide secure and instant access to popular models like Llama 2 70B Chat, Mixtral-8x7B Instruct, MPT 7B Instruct, MPT 30B Instruct and BGE Large (En) directly on Databricks. This approach is not only secure but also cost-effective, thanks to a pay-per-token model that significantly reduces operational costs. For tasks demanding specific performance benchmarks, both general and finely-tuned model variants can be deployed using provisioned throughput.
To explore the range of foundational models supported, please visit the following link for detailed information.
The Foundation Model APIs enable you to:
Develop LLM applications for either development or production environments, supported by a scalable and SLA-backed LLM serving solution capable of handling spikes in production traffic.
Efficiently evaluate different LLMs to determine the most appropriate choice for your specific needs, or to replace a currently deployed model with one that offers superior performance.
Transition to open-source model alternatives from proprietary ones to enhance performance while reducing costs.
Utilize a foundational model in combination with a vector database to develop a chatbot that employs retrieval augmented generation (RAG).
Use a general LLM for creating an immediate proof-of-concept for LLM-based applications before the commitment of resources to train and deploy a custom model.
Apply a general LLM to confirm the viability of a project prior to allocating additional resources.
Integration of External Models
The platform isn't limited to internal models. With External Models, Databricks Model Serving allows for the integration of models hosted outside of Databricks, such as those from Azure OpenAI GPT models, Anthropic Claude Models, or AWS Bedrock Models. Once added, these models can be managed from within Databricks. This flexibility ensures that businesses can manage and monitor all their AI models from a single interface, simplifying administration and fostering innovation.
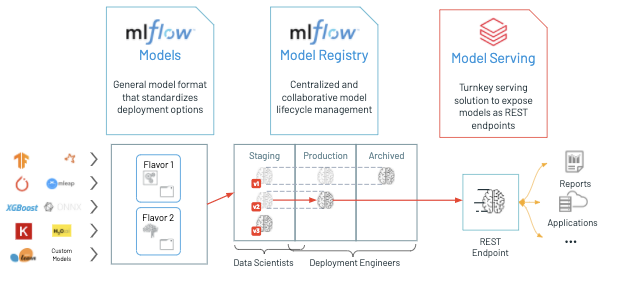
Databricks Model Serving leverages a cohesive data and AI framework, offering comprehensive management of Large Language Model operations (LLMOps) within a single ecosystem. This includes every phase from data ingestion and model refinement to deployment and ongoing surveillance, ensuring a unified perspective throughout the AI lifecycle to expedite deployments and reduce inaccuracies.
The service seamlessly integrates with a variety of LLM functionalities within the Lakehouse ecosystem, such as:
Fine-Tuning: Enhance model precision and uniqueness by refining foundational models with your exclusive data directly within Lakehouse.
Vector Search Integration: Effortlessly conduct vector searches to support retrieval augmented generation and semantic search applications.
Built-in LLM Management: Incorporates with the Databricks AI Gateway, serving as the principal API layer for all LLM interactions.
MLflow: Utilize MLflow’s PromptLab for the evaluation, comparison, and management of LLMs.
Quality & Diagnostics: Requests and responses are automatically logged in a Delta table for model monitoring and troubleshooting. This information can be enriched with your labels to create training datasets, thanks to a collaboration with Labelbox.
Unified Governance: The Unity Catalog facilitates the management and regulation of all data and AI assets, both ingested and generated by Model Serving, streamlining oversight across your projects.
Centralized and Unified Model Management with Databricks Model Serving
In terms of unified management, Model Serving brings together a wide range of models under a single user interface and API. Whether models are hosted on Databricks or through other model providers on platforms such as Azure and AWS, Databricks Model Serving ensures seamless access and management, consolidating the diverse landscape of AI models into one accessible and navigable platform.
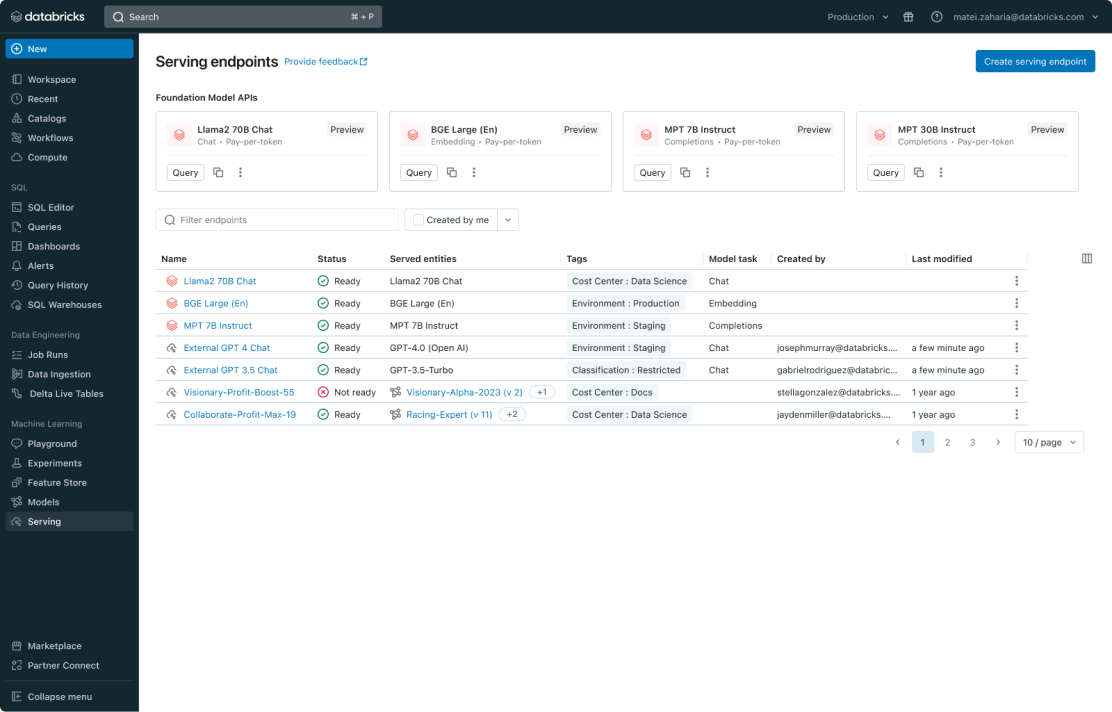
Databricks' unified approach makes it easy to experiment and produce models from any cloud or vendor to find the best candidate for your application in real time. You can A/B test different models and monitor the quality of models on live production data once deployed.

Security Measures: Safeguarding Your Data
Databricks Model Serving is designed with stringent data protection measures to ensure the security and privacy of customer data. Here's an overview of the security controls implemented by Databricks to safeguard your data:
1. Logical Isolation of Customer Requests: Each request to Model Serving is treated with high levels of isolation. This ensures that data from one customer does not mix with data from another, maintaining data integrity and confidentiality.
2. Authentication and Authorization: Databricks requires that every request to Model Serving is authenticated and authorized. This step verifies the identity of the requester and ensures that they have the necessary permissions to access the requested data or service, adding an additional layer of security.
3. Encryption of Data at Rest and in Transit:
At Rest: Databricks encrypts all stored data using AES-256, a robust encryption standard that offers a high level of security.
In Transit: All data moving to and from Databricks Model Serving is encrypted using TLS 1.2 or higher, protecting data from interception or tampering during transmission.
4. No Use of User Inputs for Model Training in Paid Accounts: For those with paid accounts, Databricks commits to not using any user inputs or outputs submitted to Model Serving for the purpose of training its models or improving its services. This policy ensures that your data remains confidential and is used solely for the purpose it was intended for.
5. Temporary Processing and Storage for Foundation Model APIs: In the case of Databricks Foundation Model APIs, while Databricks may process and store inputs and outputs temporarily, it's strictly for the purposes of preventing, detecting, and mitigating abuse or harmful uses. Key points include:
Data Isolation: Your data is kept separate from that of other customers, ensuring privacy and reducing risk of data leakage.
Regional Storage: Inputs and outputs are stored in the same region as your workspace, aligning with data residency preferences and regulations.
Limited Storage Duration: Data is stored for up to thirty (30) days, after which it's deleted, minimizing the risk of exposure over time.
Security and Abuse Mitigation: Access to this data is strictly controlled and limited to purposes related to detecting and responding to security or abuse concerns.
Through these measures, Databricks ensures that your data is protected across multiple dimensions, addressing concerns related to data integrity, confidentiality, and privacy.
Databricks Workspace
To interact with LLMs in an intuitive and direct manner, we recommend using the AI Playground feature available in your Databricks workspace. AI Playground acts as a conversational interface, allowing you to experiment, pose questions, and assess different LLMs effectively and comparatively.
Follow these steps to begin exploring the capabilities of LLMs within the AI Playground:
Navigate to Playground: Within the Machine Learning section found in the left sidebar of your Databricks workspace, click on "Playground."
Choose Your Model: At the top left corner of the Playground, there's a dropdown menu. Use it to select the LLM you wish to engage with.
Engage with the Model - You have a couple of options for interaction:
> Enter your custom question or prompt directly into the provided text field.
>> Choose from a list of predefined AI instructions displayed within the Playground for a quick start.
Expand Your Comparison: By clicking the "+" symbol, you have the option to add another model endpoint. This feature enables the side-by-side comparison of responses from multiple models, enhancing your ability to evaluate their performance.

Source: Databricks & SunnyData Edition
Final Conclusion
To sum up, Databricks equips users with a comprehensive suite of capabilities for managing the lifecycle of LLM models efficiently with a significant emphasis on security. It supports both CPU and GPU environments to ensure optimal training conditions and is finely tuned to enhance cost-efficiency, minimizing expenses related to training and utilization. Importantly, it offers thorough governance and oversight across the entire AI model lifecycle.
Keep an eye out for upcoming articles where we'll delve deeper into Generative AI and AI Governance within the Databricks ecosystem.