Redshift to Databricks - Part 1: Why and How to Start Your Migration
Welcome to our comprehensive guide on migrating from Amazon Redshift to Databricks. To provide a thorough understanding of both the strategic and technical aspects of this migration, we have structured this guide into two detailed blog posts.
Part 1 (Why and How to Start Your Migration to Databricks): In the first part, we will delve into the foundational concepts behind the migration. We’ll explore the reasons why organizations are making the switch to Databricks, the benefits it offers over Redshift, and the key considerations to keep in mind during the planning phase. This section is designed to help you understand the “why” and “what” before moving on to the “how.”
Part 2 (Technical Implementation Guide): The second part will focus on the technical steps required to execute the migration successfully. We’ll provide a step-by-step guide covering data transfer methods, schema conversion, query optimization, and best practices to ensure a smooth transition. This section is tailored for technical professionals who are ready to dive into the “how” of the migration process.

Understanding Amazon Redshift
Amazon Redshift is a data warehouse launched by AWS in October 2012, which has been well-received in the market, primarily driven by the success of AWS as a cloud provider and the decision of its customers to utilize AWS’s native services. According to Forrester reports from Q4 2018, Amazon Redshift had the highest number of cloud data warehouse implementations (around 6,500), positioning itself ahead of other traditional data warehouses like BigQuery, Snowflake, and Teradata.

From a technical perspective, Amazon Redshift is designed to handle large volumes of data and perform complex analytics efficiently. It employs a massively parallel processing (MPP) architecture to distribute and process data across multiple nodes, and uses a columnar storage structure to maximize data-reading efficiency by accessing only the relevant columns needed for a query.
The initial version of Redshift was based on an older version of PostgreSQL 8.0.2, upon which Amazon has introduced numerous improvements and evolutions over time.
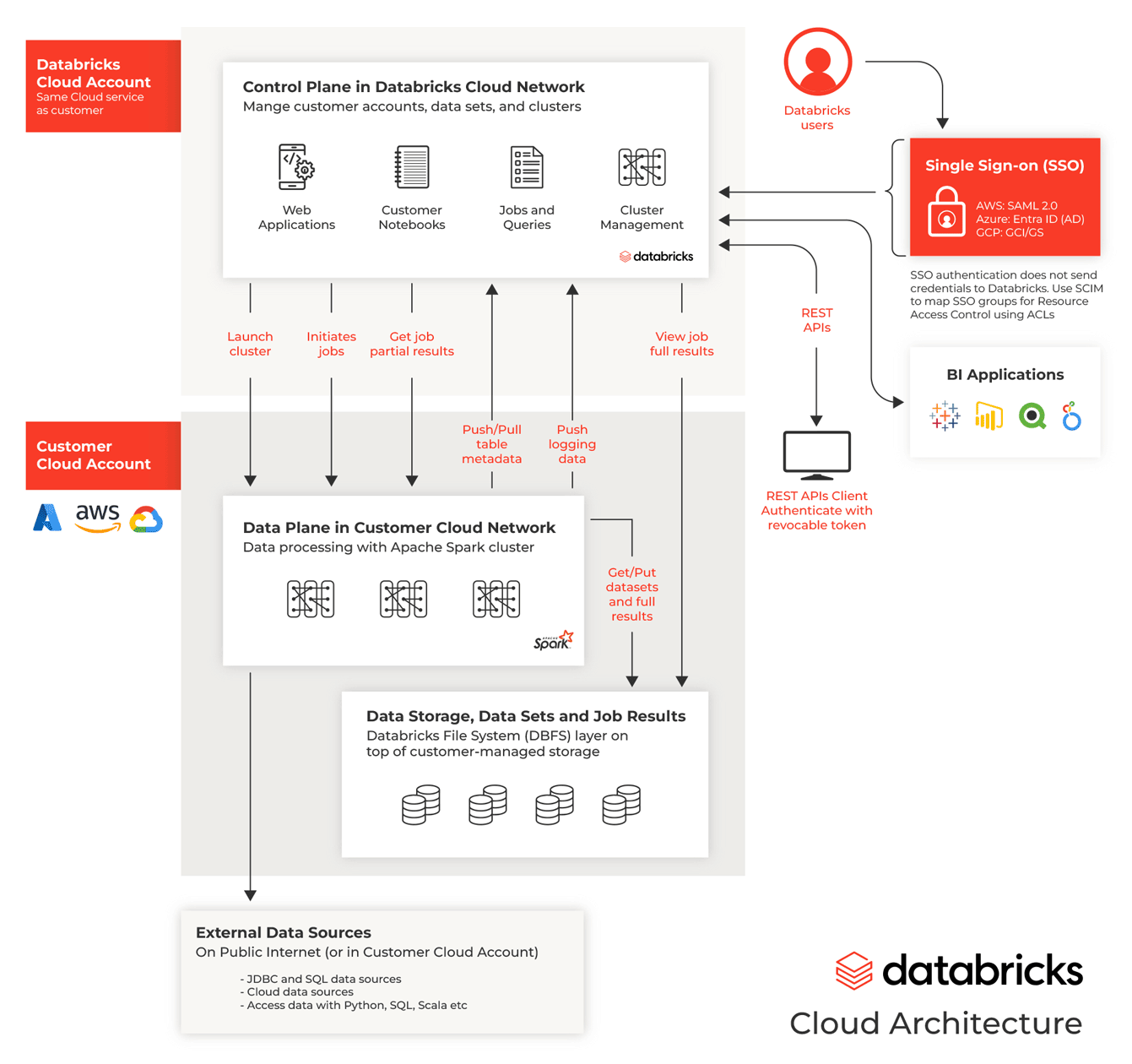
Redshift is designed to integrate seamlessly with other services in the AWS ecosystem— Glue, EMR, Lake Formation—and to communicate with various storage sources such as Amazon Aurora and Amazon S3. This integration has been a key factor in the adoption of Redshift by many companies during their cloud migration process.
Challenges with Amazon RedShift
Amazon Redshift has the oldest architecture among the first cloud data warehouses and, as a result, lacks some features that became popular later and that modern users now consider essential, such as the separation between compute and storage. This is because Amazon acquired the source code of ParAccel (which was later acquired by Actian), itself based on an older version of PostgreSQL (as mentioned in the previous paragraph). The decision to build on this legacy code base and thus inherit core limitations has led to recurring criticism within the community, where users express dissatisfaction with aspects such as performance and cost-effectiveness.
Amazon Redshift has the oldest architecture
I’ve read comments online that criticize Amazon Redshift, saying things like: “It’s horrible,” “if your average CPU usage is 10%, you’re paying 5 times more than with another platform,” “Redshift isn’t bad, but it’s worse than everything else,” “the documentation is bad,” and “Amazon isn’t investing in it, and it’s falling behind.” There are other comments I won’t cite to maintain the formal tone of the article.
From my perspective, while many of these criticisms are valid, I believe the reputation that Amazon Redshift has acquired is somewhat unfair if we don’t consider the context. It’s important to understand that it’s challenging for any cloud provider to offer solutions that are leaders in every aspect. The key is to provide an integrated ecosystem that can meet diverse needs, even if not every service is the best in the industry.

In fact, many companies that started their cloud adoption process with AWS, migrating their applications, found Amazon Redshift to be a suitable service for leveraging their data.
Primarily because it fulfilled the objective that companies had years ago: to generate reports and perform complex queries without affecting their production databases.
Legacy Architecture and Compute-Storage Limitations
Amazon Redshift, as we mention, has an older architecture compared to more modern platforms like Databricks or Snowflake. A significant limitation is the lack of full separation between compute and storage. In newer platforms, compute and storage are decoupled, meaning they can scale independently based on workload demands. This allows for greater flexibility and cost-efficiency, as users can allocate only the resources they need without over-provisioning.
While Redshift’s RA3 instances introduce some level of separation by allowing compute nodes to scale while caching only the required data locally, the architecture still ties compute operations too closely with storage in certain scenarios. This results in inefficiencies, particularly for fluctuating workloads or when the isolation of compute resources is required. In Redshift, it’s not possible to isolate different workloads over the same data as efficiently as with fully decoupled architectures, putting it behind more adaptable systems like Databricks.

Limited Scalability: Even with RA3 instances, Redshift struggles to scale efficiently for high concurrency. It can only queue a maximum of 50 queries, which may cause delays during peak workloads
Concurrency Limitations: Redshift’s ability to handle multiple workloads concurrently is limited, especially under heavy usage, which can result in degraded performance
Performance Issues: Redshift does not perform significantly better than other cloud data warehouses in benchmarks. It lacks index support and comprehensive query optimization, making low-latency analytics difficult to achieve at scale
High Costs Due to Inefficient Resource Usage
One of the most notable drawbacks of Amazon Redshift is its potential for high operational costs, particularly when compute resources are not fully utilized. Redshift requires users to provision clusters based on anticipated peak usage. However, if the actual usage is lower (for example, if CPU utilization averages below 20% maybe you’re paying 5 times more than with another platform), organizations are effectively paying for idle resources.

Unlike Databricks, which can dynamically scale compute resources based on real-time demand, Redshift does not automatically reduce capacity during low activity periods. This can lead to overprovisioning and higher costs. For instance, companies that configure Redshift to meet high-performance demands during peak times but do not consistently use that capacity will likely end up paying more than they would with a more flexible platform like Databricks.
Redshift’s cost model is more static and less adaptable to varying workloads, resulting in significantly higher operational costs for businesses with fluctuating demands.
Batch-Centric Ingestion: Redshift is optimized for batch ingestion but lacks robust support for continuous data ingestion, making it less suitable for real-time analytics, especially when compared to Databricks, which excels in such scenarios.
High Cost for Low Utilization: Redshift can become particularly expensive when utilization is low, as the platform does not efficiently scale down resources to match actual usage.
Lack of Interactive Query Capabilities: Redshift is less effective for interactive and ad-hoc queries, especially in comparison to more modern data warehouses optimized for such use cases.
Programming Language Limitations
While Redshift is optimized for SQL, its support for other languages like Python is restricted. Although Python can be used through User Defined Functions (UDFs), these are not fully integrated and are more limited compared to platforms that natively support additional languages, reducing flexibility for developers.
Limited Support for Semi-Structured Data
Redshift allows for the use of formats such as JSON, but it is not optimized for handling large volumes of semi-structured data. Complex queries on these formats can be slow, affecting performance compared to more modern platforms that are specifically optimized for semi-structured data processing.
Complexity in Management
Redshift requires significant manual intervention for configuration and performance tuning. While it offers many optimization options, they demand a high level of manual administration, making it more challenging compared to platforms that provide more automation and ease of management.
Real-Time Querying and Stream Analytics
Redshift is not well-optimized for real-time queries or continuous stream analytics. While it handles batch operations efficiently, its performance suffers significantly when real-time processing is required, making it less suitable for applications that need immediate responses.
Inconsistent Performance with Complex Data
As datasets grow in size and complexity, Redshift tends to struggle with maintaining consistent performance. Queries often become slower without frequent manual adjustments, such as optimizing through sort keys and distribution keys, requiring considerable effort in management and tuning.
So, Why Migrate from Redshift to Databricks?
The comparison between Amazon Redshift and Databricks is not entirely fair due to the fundamental differences in their approaches and purposes. Amazon Redshift is a data warehouse, primarily designed to store and process large volumes of structured data, focusing on analytical queries and report generation.
In contrast, Databricks is a Lakehouse platform, which combines the best aspects of data lakes and data warehouses and is designed to handle the entire data ecosystem, from ingestion and storage to advanced analytics and artificial intelligence.
In this sense, a more appropriate comparison would be between Amazon Redshift and Databricks SQL, which is the specific layer of Databricks for SQL queries and structured data analysis. However, even this comparison is not entirely accurate, as Databricks has a much more comprehensive focus. Databricks not only offers SQL capabilities for structured data analysis but also supports the processing of unstructured data, streaming, machine learning, and real-time analytics, positioning itself as a unified platform that covers the entire data lifecycle.
In contrast, Redshift is more focused on traditional structured data storage and analytics.
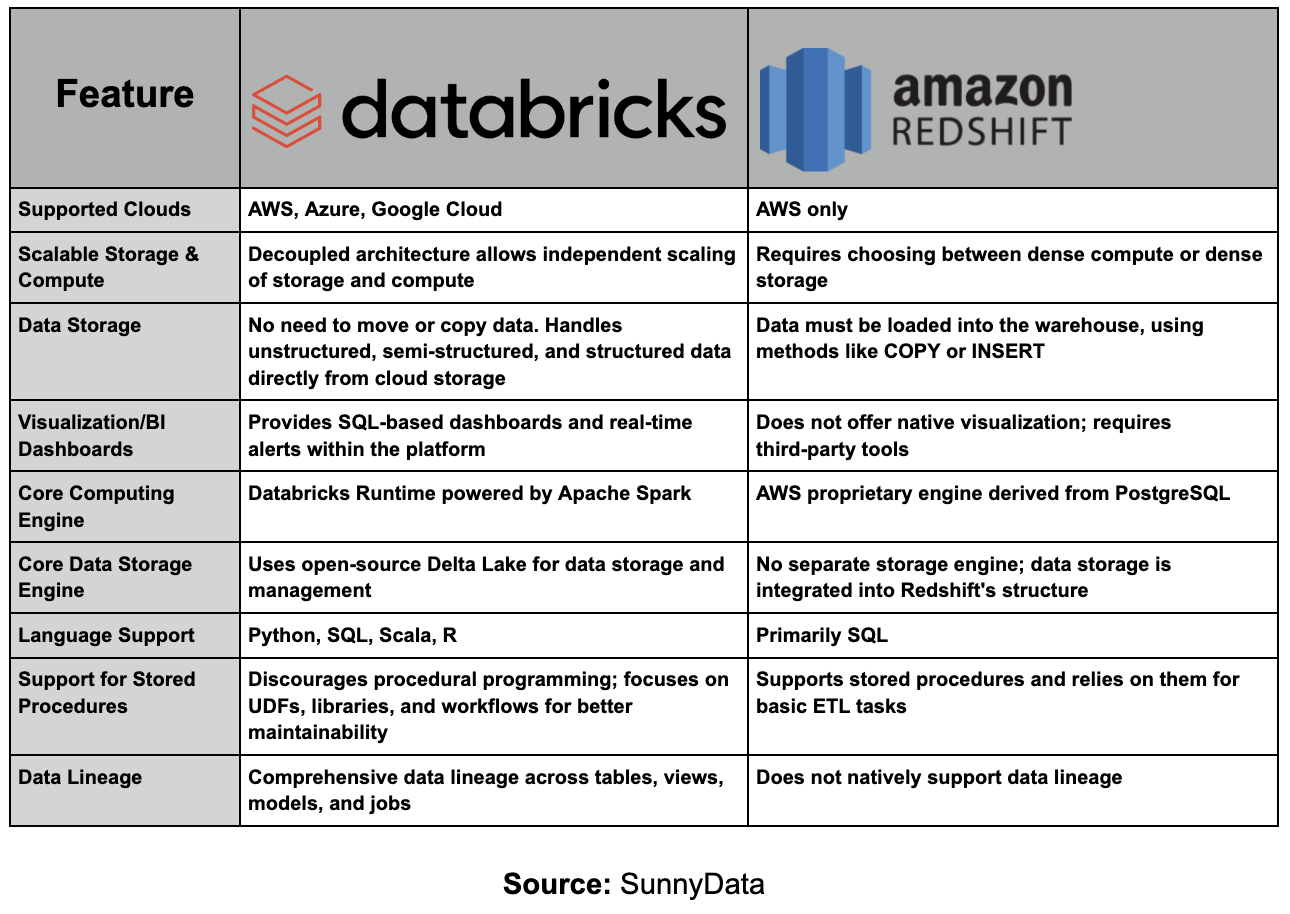
Databricks effectively addresses many challenges faced by data professionals through its agnostic design, offering unmatched versatility across critical dimensions.
Firstly, it is cloud-agnostic, seamlessly integrating with AWS, Azure, and Google Cloud. This flexibility allows organizations to choose the cloud infrastructure that best suits their needs without being locked into a single provider—an invaluable feature for businesses operating in multi-cloud environments or adapting to evolving cloud technologies.

Secondly, Databricks is programming language-agnostic, supporting Python, R, SQL, and Scala—even within the same notebook. This empowers data professionals from different backgrounds to collaborate more effectively, fostering an inclusive environment where each team member can work in their preferred language.
Whether building complex machine learning models or running large-scale SQL queries, Databricks ensures the necessary tools are readily available.

Moreover, Databricks excels in both batch processing and real-time data ingestion due to its Delta Lake architecture, which ensures high performance and reliability.
Being agnostic to processing modes is crucial for organizations that need to support both historical data analysis and real-time decision-making within the same platform.
Additionally, Databricks is role-agnostic, catering to data engineers, data scientists, and business analysts by providing a unified platform for building ETL pipelines, running machine learning models, and conducting advanced analytics.

Finally, Databricks offers excellent scalability and cost management. Its architecture separates compute and storage, allowing businesses to scale resources independently and optimize costs. The platform also supports serverless computing, enhancing its ability to scale efficiently based on workload demands.
This ensures that businesses can maintain high performance while keeping costs under control, even as their data processing needs grow.
What to Consider Before Migrating from Amazon Redshift to Databricks
This second section of the blog will continue next week, as there is undoubtedly a strong connection between the ‘What’ and the ‘How’ of the migration. For now, we will avoid diving deeply into technical details.

Introduction to the ‘What’ of the Migration
Successfully migrating from Amazon Redshift to Databricks requires careful planning and execution. A well-structured approach helps minimize risks and ensures a smooth transition.
The optimal migration path will depend on several factors, including
Current Architecture: One of the most important considerations when planning a migration is understanding the existing architecture, including dependencies on other AWS services and third-party tools. Amazon Redshift, as a data warehouse, often relies on a broader ecosystem to function optimally.
For example, Redshift is typically used alongside AWS Glue for data ingestion and ETL processes, or with AWS Lake Formation for data cataloging and governance. Databricks integrates well with tools such as Glue or Amazon Kinesis for real-time data ingestion, and many of these artifacts can be reused (we will dive deeper into this next week). AWS S3 is also commonly used for data storage, serving as the backbone for storing raw, processed, and analytical data for both Redshift and Databricks workflows.
Workload Types: The type of workloads running on Redshift will also play a major role in shaping the migration approach. Redshift is primarily a data warehouse designed for structured, analytical queries, often supporting BI dashboards, ETL processes, and batch analytics. However, organizations increasingly need platforms that can handle diverse workloads, including machine learning (ML) pipelines, real-time data processing, and ad-hoc querying of semi-structured data.

Business Criticality: Business-critical use cases need to be given special attention during migration, as any disruption to these workflows can have significant consequences. For instance, a financial institution using Redshift to generate regulatory compliance reports or BI dashboards for real-time decision-making will need to carefully plan the migration to avoid downtime or performance degradation.
For such critical use cases, a phased migration approach—migrating non-critical workloads first—might be the best strategy. This allows organizations to test and validate the migration process on less essential tasks before moving mission-critical workloads.
Ongoing Projects: It’s important to align the migration timeline with other ongoing or planned projects to minimize the risk of disruption. In some cases, the migration might need to be delayed or segmented to accommodate other high-priority initiatives. For instance, if there are major product launches or regulatory audits happening during the migration, it might be wise to pause or break the migration into smaller phases.
Migration Objectives: Clearly defining the objectives of the migration is critical to its success. Whether the goal is to reduce costs, meet a cutover deadline, or enhance capabilities (such as enabling machine learning or real-time analytics), these objectives will guide every stage of the migration process.

Cost reduction is often a major motivator, as Redshift’s pricing model requires organizations to provision clusters upfront, leading to potential over-provisioning and higher costs.
Databricks offers more flexible pricing, allowing compute and storage to scale independently, which can significantly reduce costs for workloads that fluctuate in intensity.
Migration Strategies
While there are two primary strategies for migrating from Amazon Redshift (or any other platform) to Databricks—a big-bang migration and a phased migration—our focus will be on the phased approach. The phased migration strategy is particularly relevant for the vast majority of clients, offering several advantages that make it the preferred method for most scenarios.
Phased Migration involves migrating data and workloads in stages, such as by specific use cases, schemas, or data pipelines. This approach mitigates risks, demonstrates incremental progress, and allows businesses to validate and adjust their migration strategy as needed. For organizations with complex data architectures, multiple databases, or several business teams relying on data, a phased migration provides the opportunity to manage the transition without disrupting ongoing operations.
While a big-bang migration may be faster, it is generally suited to simpler environments with smaller data footprints or when the migration scope is limited. Additionally, in some specialized cases, such as software migrations from platforms like SAS, a big-bang approach might be necessary due to licensing constraints. However, such scenarios do not apply to Amazon Redshift, which doesn’t involve licensing issues. As a result, the phased migration is a much safer, more flexible strategy for most Redshift users.

Before fully launching the project (Phase 5) and defining the low-level strategy, we will initially focus on the earlier phases. First, we need to understand the current state and the objectives (Phase 1), followed by designing the solution (Phase 2), and then proposing a clear migration strategy (Phase 3). The initial goal will be to implement a productive pilot (Phase 4) that validates the project’s feasibility, particularly in terms of time and return on investment (ROI), leading to the full project execution (Phase 5).
Each of these phases will be detailed in the next blog post with deeper technical insights, but for now, we will focus on the initial phase.
Phase 1: Discovery
The best way to approach a Discovery phase is through a combination of experienced personnel with previous migration knowledge and the use of accelerators that streamline the process of gathering information from the source platform. This, along with established practices and methodologies, helps to properly structure the necessary actions. For example, Databricks provides questionnaires that assist in collecting key data, such as identifying the machines in Redshift to configure the equivalent clusters in Databricks.
Assessing the Current Situation

Amazon Redshift Profiler - It is highly recommended to use an accelerator tool to gain a clear understanding of your Amazon Redshift environment, allowing for more effective migration planning. Databricks provides built-in accelerators specifically designed to map the source system and deliver a comprehensive analysis.
The Redshift Profiler examines key elements such as workload types, long-running ETL processes, and user access patterns, offering a detailed breakdown of the system’s complexity—categorized as high, medium, or low. This allows for the prioritization of workloads and helps to identify potential challenges in the migration process.
These types of accelerators provide critical visibility into databases and pipelines that may drive up costs or increase complexity, making them ideal for organizations looking to optimize performance and reduce migration risks.
Static Code Converters vs SunnyData’s GenAI based accelerator for ETL/EDW migration
The typical approach used by most consulting firms for ETL code conversion often relies on static tools (several in the market) along with throwing bodies at the problem, which results in costly($$$$) and lengthy conversion projects.
In this traditional method, static hard coded converter software is used to analyze the ETL code repository and plan the project effort. While the code conversion is done through a semi-automated converter, it still requires the support of a systems integrator (SI) to address conversion gaps and conduct testing, adding an extra layer of complexity to the process.
This method heavily relies on manual expertise to ensure that the ETL scripts and processes are correctly transformed and validated.
In contrast, SunnyData’s approach leverages GenAI for code conversion combined with our internal IP, which reduces the cost and time burden on complex EDW migrations. We leverage GenAI tools (such as Claude 2.0, DBRX, and ChatGPT) to discover, assess, and convert the core business logic which accelerates and shrinks the EDW migration timeline and cost burden on migrations:
Automate discovery and documentation : LLMs can take the legacy ETL code as source code (XML or JSON output from legacy ETL tools or source code in SQL or other languages) and speed up the discovery, assessment, documentation and onboarding of consultants on the project.
Automated Conversion of legacy ETL code to Databricks (Python, PySpark or DBSQL) : Leveraging the latest GenAI tools in a governed way through the Databricks platform, legacy ETL code can be converted to the Databricks platform and the preferred data engineering language. As an example, some of these LLMs already come pre-trained with the specific flavor of ETL tools from Informatica (PowerCenter, ICDM, Data Quality, DEI).
SunnyData’s QA accelerators that are highly automated and configurable compare data in the legacy EDW to the data in the Lakehouse (schema, tables, columns, data types, data volume, variations through statistical analysis) to identify errors, but more importantly accelerate the QA processes.
Conclusions Part 1 (Why and How to Start Your Migration to Databricks)
We’ve reached the end of this first part of the blog. By now, we have a clear understanding of what Amazon Redshift is, the challenges it presents, and why migrating to Databricks could offer a more comprehensive solution while maintaining key synergies within AWS. We’ve also explored critical migration aspects and initiated phase 1 (discovery and initial analysis).
We’ll continue with more details next week. Thank you all for reading! See you next week.