Redshift to Databricks - Part 2: Technical Implementation Guide
This article is the second installment in our series on migrating from Redshift to Databricks. If you’re beginning this journey, we strongly recommend reading the first blog before diving into this one, as it provides essential context, outlines the initial steps of the transition, and highlights the benefits of making the switch.
Note: Part 1 is geared toward business audiences or those who won’t be directly executing the technical migration.) You can find Part 1 here: Redshift to Databricks: Why and How to Start.

As we discussed in Part 1, migrating EDWs and ETL processes from traditional on-premises systems to the cloud is often a complex and time-intensive process. However, migrating from Amazon Redshift to Databricks is comparatively more straightforward, as the data is already cloud-based, eliminating many of the challenges associated with on-premises transitions.
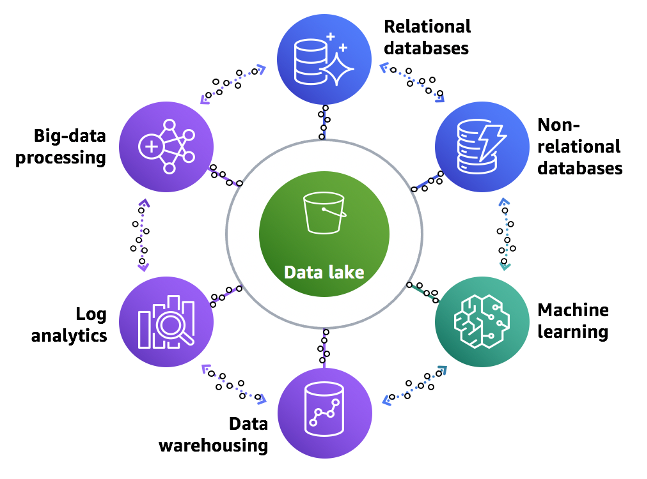
In the previous blog, we explored Redshift and Databricks, assessing their strengths and weaknesses to set the foundation for the migration journey. With this understanding in place, we began the essential first step: the discovery phase.
In this article, we’ll revisit this initial phase, expanding on what we’ve previously discussed (while omitting accelerators and topics already covered) to help re-contextualize readers in the migration stages and provide additional insights.
From Discovery to Action: Phase 1
This phase involves conducting in-depth migration assessments to understand the specific requirements and complexities involved. During discovery, gathering key information is crucial to effectively guide the migration process. Before moving any data or workloads, these assessments provide a comprehensive view of the migration landscape, enabling informed decisions at every stage.
To streamline the information-gathering process, we recommend using accelerators, which can expedite assessments. However, regardless of the tools or methods used, the essential objective remains the same: to obtain the following critical insights.
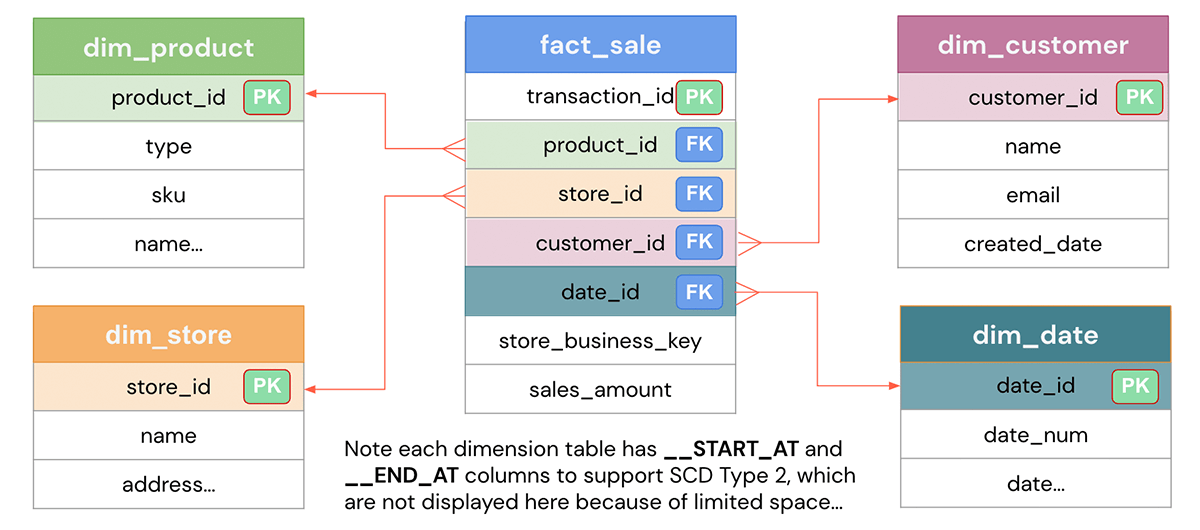
Key Steps in the Discovery Phase
Now that we’ve established the importance of the discovery phase, let’s dive into the key steps that will effectively guide your migration process.
1. Identify Workloads and Catalog Complexity
First, it’s crucial to pinpoint the types of workloads involved in your current setup, such as:
ETL Processes: Extract, Transform, Load operations that move and transform data.
Business Intelligence (BI): Analytical tools and reporting systems.
Data Ingress/Egress: Data flowing into and out of your systems.
Understanding these workloads and their sizes across different warehouses and databases helps you grasp the volume and nature of the tasks to be migrated. This forms the foundation for estimating the required effort and resources.
Note: A good practice is to categorize workloads by complexity and purpose, allowing you to prioritize use cases that align with business needs and establish a migration plan that gradually increases in difficulty. This approach may avoid tackling the most complex workloads at the outset and focuses on delivering impactful results early in the process.

# TIP 1: Positioning Yourself for Success
Gathering insights from these assessments positions you for success by clarifying the complexity and scope of the migration effort. This preparatory phase enables you to make data-driven decisions, prioritize workloads that maximize business value, and allocate resources efficiently.
2. Data Evaluation
Next, it’s essential to assess the scope, structure, and performance of the data and queries to be migrated. A comprehensive data evaluation helps prioritize critical workloads, optimize migration planning, and anticipate potential challenges:
Determine Essential Data and Workloads: Identify the data, tables, and workloads crucial to your operations and prioritize them for migration. This step is connected with the last one, but is important to highlight how important it is to understand the actual data model, tablas involved, etc.
Catalog Tables and Structure: Identify and catalog tables across each database, noting dependencies, relationships, and any structural complexities (such as high levels of normalization) that may require additional transformation and optimization.
Assess Data Volume & Quality: Measure data volume at both the table and workload levels to estimate storage and processing needs in the new environment. In a Redshift-to-Databricks migration within AWS, the data is already in the cloud, so data migration logistics may not even be necessary. However, it’s essential to emphasize data quality checks throughout the migration process, as these ensure reliable performance and accuracy in the new setup.
Assess Associated Queries: Evaluate the queries related to each dataset, assessing their frequency and complexity.
Analyze Query Performance and Usage Patterns: Identify high-frequency queries and analyze their structure, note workload scheduling and frequency (such as ETL jobs, reports, and data transfers), and pinpoint peak usage times to optimize resource allocation and schedule design in Databricks.
Having a precise scope allows for more accurate planning and helps anticipate potential challenges that might arise during migration.
# TIP 2: Stay Adaptable
It’s important to note that your initial migration plan may need adjustments based on discoveries made during this phase. Maintaining an adaptable approach ensures alignment with the realities of your data and infrastructure, ultimately leading to a more successful migration.
3. Map Upstream and Downstream Dependencies
Mapping out the dependencies within your data ecosystem is another critical step:
Technologies: Identify software and tools that interact with your data.
Applications: Note any systems that rely on or feed into your data warehouses.
Connected Processes: Understand workflows that could be affected.

Since many components that depend on Redshift may be reusable (depending on the defined migration strategy, whether it’s a direct lift-and-shift or a more extensive refactoring), matching these components accurately is essential. This mapping will be revisited in the next phase to confirm compatibility and further refine integration plans.
4. Review Security Protocols
Security is paramount during migration, especially when moving from Redshift to Databricks within AWS. Key actions include:
Evaluate your current security setup: Start by identifying potential vulnerabilities in the current Redshift configuration, reviewing user roles, permissions, and network settings to detect any security gaps.
Align with Databricks Security Requirements: To ensure security continuity, adapt user roles and permissions as they transition to Databricks, implementing RBAC and MFA if not already in place. Align data governance policies from Redshift to Databricks by setting up data classification, lineage tracking, and access logging, which helps maintain data integrity and traceability. A good practice is to use Unity Catalog from scratch in Databricks.
Ensure compliance with regulatory standards and industry best practices: To maintain regulatory compliance, verify alignment with industry-specific standards like GDPR, HIPAA, and SOC 2, adapting policies in Databricks to fulfill these requirements. If applicable, implement or verify data masking and anonymization features to safeguard sensitive information effectively.
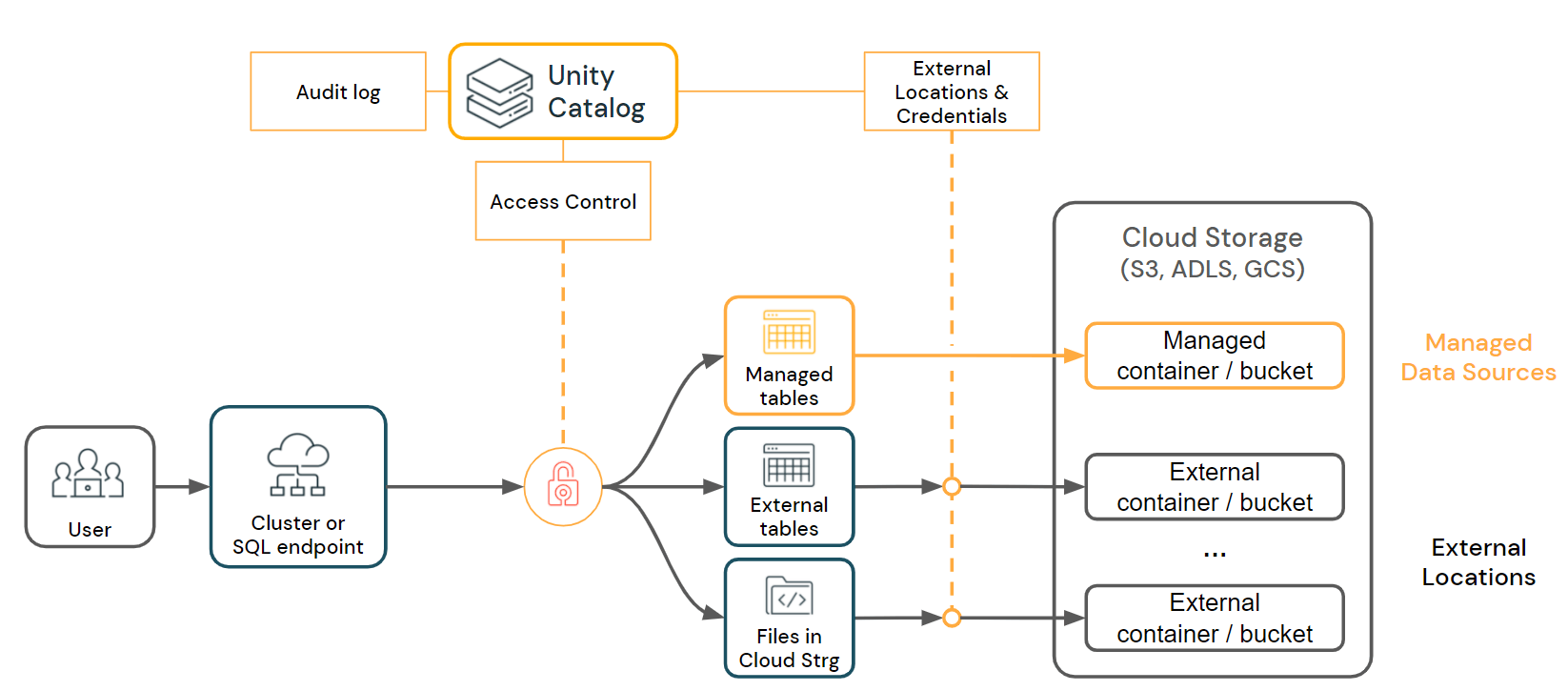
This provides a secure foundation in the new environment and builds trust with stakeholders.
5. Estimate Infrastructure Costs
Carefully estimating infrastructure costs for the migration ensures that resources are effectively allocated, and the investment aligns with expected returns. Important considerations include:
Anticipate budget needs to allocate resources effectively: To allocate resources efficiently, assess storage and compute costs in Databricks. Storage needs should be similar, with some allowance for any duplicated or transformed datasets. Evaluate compute resources based on Redshift’s current usage, adjusting for workload demands and Databricks’ potential performance gains.
Justify the investment by aligning costs with expected benefits: A well-planned cost-benefit analysis is crucial to demonstrate the return on investment for the migration. Compare the projected costs in Databricks to the expected benefits to justify the expenditure.
Plan for scalability to accommodate future growth: To ensure the migration supports future business growth, plan for scalability in both storage and compute resources. Estimate data growth trends and plan how Databricks’ flexible scaling capabilities can meet these expanding needs without major reconfiguration.
Understanding the financial aspect ensures resources are aligned with migration goals and that the process delivers significant value to the organization.

# TIP3: Leverage Databricks Tools Like Unity Catalog, Serverless, and DLT.
Maximize cost efficiency, performance, and ROI by implementing end-to-end best practices. Key Databricks tools, such as Unity Catalog for data governance, Serverless for dynamic resource allocation, and Delta Live Tables (DLT) for automated data pipelines, can optimize your migration and streamline operations across the platform.
You can achieve significant cost savings by applying best practices and implementing FinOps strategies, which help manage cloud spending efficiently and maximize value from your investment.
Designing the Target Architecture: Phase 2
Once the initial discovery phase is complete, it’s time to plan the migration from Amazon Redshift to Databricks. This phase is crucial because Redshift environments are often integrated with various AWS services and third-party tools, requiring a careful assessment of each component. Depending on the defined migration strategy, several existing services may be reusable, eliminating the need to rebuild the entire infrastructure from scratch.
Different approaches can be considered here, such as a straightforward lift & shift, application refactoring, or simpler cases where only disconnection and reconnection are required, as with BI tools like Power BI, which may operate “without huge modifications”. The choice of strategy depends on multiple factors, including the level of dependency on current systems, modernization goals, and the performance desired in the new environment.
Databricks recommends fully leveraging its capabilities, including tools like Unity Catalog for data governance, Delta Live Tables (DLT) for automated data pipelines, and Autoloader for data ingestion for example. However, in some cases, third-party tools, such as AWS Glue for data ingestion or Fivetran, can also be integrated and reused as needed, depending on the migration strategy.
The objective of this phase is to design a clear, tailored modernization roadmap. Comparing the current and future architectural diagrams is essential to identify the intermediate steps needed. For instance, during the migration, it may be necessary to run data transformation pipelines in both Redshift and Databricks to maintain consistency and minimize downtime. In such cases, solutions will need to be developed to synchronize data, ensuring that external systems continue to operate smoothly.
To shape this strategy effectively, it’s necessary to anticipate potential setbacks and outline how they will be addressed. This structured analysis should be incorporated into the migration plan, detailing the specific steps to enable a seamless transition with minimal disruptions. This phase is where the migration strategy truly takes shape, defining the technical and operational processes needed to execute the shift effectively.

Using the insights gathered in Phase 1, we’ll map each feature from Redshift to its equivalent in Databricks, ensuring a seamless transition without any loss of essential functionality. The table below highlights how key features between Amazon Redshift and Databricks align, providing a clear view of compatible components for migration.
It’s worth noting that this table, shared by Databricks, is designed to compare Redshift with Databricks using the full suite of Databricks components. However, as we mentioned earlier, certain Redshift elements or tools from other vendors may still be viable depending on the migration strategy. These choices, while important, fall outside the scope of this blog, as an extensive discussion on each possible component could make this article challenging to follow.
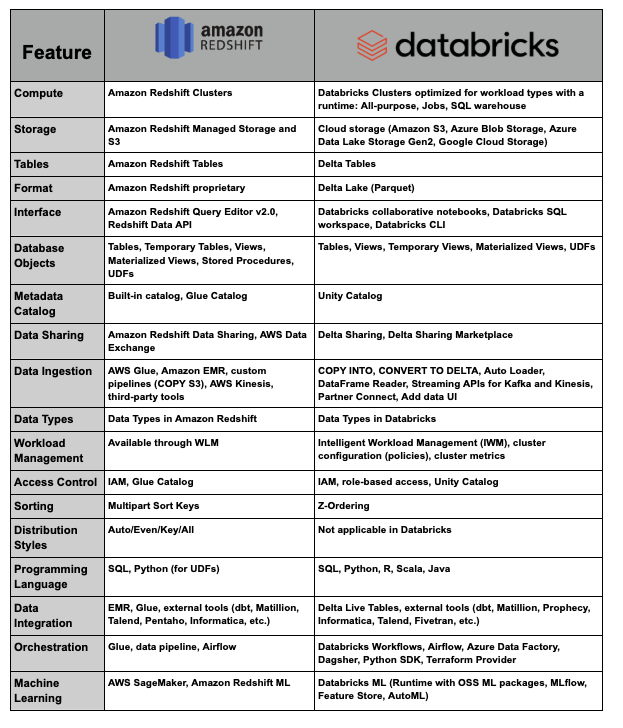
By the end of this phase, we’ll have a clear understanding of the migration’s scope and complexity, enabling us to create a precise migration plan and cost estimate.
Data Migration: Phase 3
Even though the data is already in the cloud, this doesn’t mean there’s no data migration phase involved. The first step is to create workspaces to establish the environments where we’ll be working. As a best practice, it’s generally recommended to set up multiple workspaces, which can be organized by environment (e.g., development, staging, production, QA) to facilitate a structured workflow and ensure data integrity across different stages of development.
Alternatively, workspaces can be structured by business units (such as marketing, finance, sales) or even designed to support a data mesh approach, where data is decentralized into distinct domains. This method enables teams to maintain control over their data while fostering cross-functional collaboration. Defining these workspaces early on provides a well-organized foundation for the migration process and ensures alignment with business needs and governance practices.
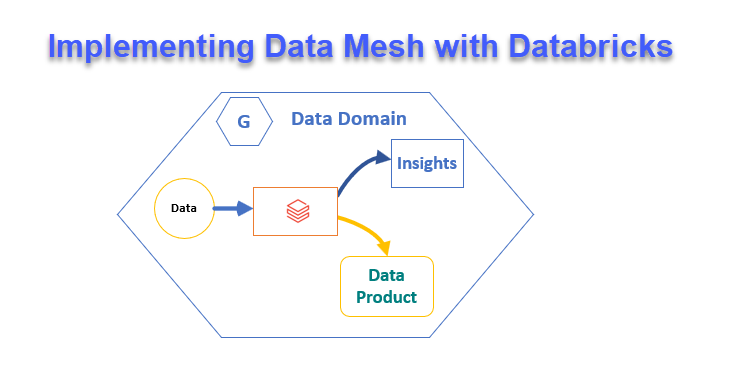
With the workspaces configured, we are one step closer to starting the gradual migration of data and metadata, following the defined migration plan by phases. It’s essential to keep in mind that Amazon Redshift uses a proprietary format, which requires careful handling.
Before beginning the actual migration, we’ll need to establish how the data structure should be organized in Databricks. Key questions include whether to maintain the same hierarchy of catalogs, databases, schemas, and tables in the destination, or if adjustments should be made to streamline or optimize the structure.
Additionally, we should consider any necessary data cleanup, such as removing duplicate datasets or reorganizing Redshift’s data footprint to better align with Databricks’ architecture. Once these structural decisions are finalized, the data migration can proceed smoothly. As a general guideline, we recommend minimizing schema changes during migration; with Delta’s Schema Evolution feature, schema modifications are often best implemented after the data is loaded into Delta, allowing for gradual adjustments over time.
Schema Migration

Before moving tables to Databricks, it’s essential to set up the schema in advance. If you have existing DDL scripts, you can adapt them with minor adjustments to align data types with Databricks’ requirements.
Data Modelling in the Lakehouse
Data in Redshift often originates from sources like Amazon S3, Amazon EMR, or Amazon DynamoDB and follows specific data models, such as dimensional or data vault models. These can be implemented in Databricks’ Lakehouse architecture with even better performance using Delta Lake. The medallion architecture (Bronze, Silver, Gold layers) structures data into stages that maintain data quality and organization.
The migration process typically involves moving EDW tables into Delta Lake’s Bronze, Silver, and Gold layers. This phased approach preserves data quality and structure, with incremental data pipelines populating each layer as needed. Any necessary backfilling can then be performed to ensure data completeness. For additional guidance on data modeling in this migration context, refer to our blog on Migrating to Snowflake, which covers data modeling principles that apply equally here:

Load Data from Redshift to Databricks
For migrating Gold tables, Databricks offers several proven approaches:
Using Amazon Redshift’s UNLOAD Command: Export data from Amazon Redshift to cloud storage in Parquet format. From there, load the data into DDL using tools like Auto Loader, the COPY INTO command, or Spark batch/streaming APIs.
Using the Spark Amazon Redshift Connector: Connect directly to Redshift and read data into a Spark DataFrame. This DataFrame can then be saved as a Delta Lake table, providing seamless integration with Databricks.
Using Data Ingestion Partners: Utilize Databricks Partner Connect options, such as Hevo, to automate data migration with no-code setup. These tools offer built-in schema management, high availability, and autoscaling to streamline the process.
Key Considerations: When migrating schema, consider Redshift’s distribution styles and sort keys, which have equivalent optimization strategies in Databricks, such as Liquid Clustering. Ensure source schema compatibility, especially for column types, to avoid unnecessary casting. Keeping schemas in sync during the transition is crucial; using a MDM tool helps manage schema changes across both platforms effectively.
Code Migration: Phase 4
Migrating data pipelines from Amazon Redshift to Databricks involves several key components:
Compute model migration
Orchestration migration
Source/Sink Migration
Query migration and refactoring
To effectively perform this migration, it is critical to understand the complete view of the pipelines, from data sources to the consumption layer, including governance aspects.
Compute Model Migration
Databricks offers greater flexibility in computing options for different pipeline needs, allowing resources to be tailored to specific data processing needs:

Types of computation in Databricks:
All-purpose: Clusters that support multiple languages and can be always-on or self-terminating rules.
Jobs: Ephemeral computation for specific tasks that is activated only while the job is running.
DBSQL, DLT and Serverless: Options for advanced computing in data warehousing and query processing.
Usage tips:
Share clusters: When tasks use the same data, sharing the cluster cache can improve performance.
Isolate clusters: For resource-hungry tasks, dedicated clusters are recommended to avoid bottlenecks.
Databricks provides extensive resources on selecting the right compute type for various scenarios, making it straightforward to align Databricks resources with those used in Amazon Redshift. This information can simplify the process of matching and optimizing compute resources during migration.
Orchestration Migration
Orchestration migration in the context of ETL pipelines focuses on transferring scheduling and flow control mechanisms to ensure that tasks execute in the correct order and at the appropriate times in the new Databricks environment. This is essential for coordinating data ingestion, integration, and result generation across workflows.
In Amazon Redshift, orchestration is often managed through services like AWS Glue, AWS Data Pipeline, AWS Step Functions, and AWS Lambda. Alternatively, it’s common to use Apache Airflow, custom Python-based scripts, or third-party tools such as Fivetran. Each of these methods enables defining and controlling the execution of tasks across different stages of an ETL pipeline.
Options in Databricks:
1. Use Databricks Workflows to re-engineer the orchestration layer, allowing you to leverage tools such as Delta Live Tables.

2. Use external tools such as Airflow, simply translating Redshift SQL queries to Spark SQL and keeping the existing orchestration.
Recommendation: Opt for Databricks Workflows to achieve enhanced integration, simplicity, and traceability. If you’re using third-party tools like Fivetran, you can continue to leverage them within the Databricks environment, seamlessly integrating with your workflows.
Data Source/Sink Migration
In Amazon Redshift, ingestion patterns often utilize S3 as intermediate storage. In Databricks, data source and sink configurations adapt to leverage Delta Lake and the platform’s native capabilities:
Source connections:
Ingestion pipelines with tools such as Fivetran can be configured to point to Delta Lake in Databricks.

Direct ingestion from S3 using Databricks Auto Loader or Spark DataFrame APIs.

Spark integrations for streaming data: Pipelines involving streaming data, such as those from Amazon Kinesis, can be transformed using Kafka integrations within Spark, supporting robust real-time processing.
Target connections:
Ingestion tools should be adjusted to output data in Delta Lake format rather than the native Redshift format, enabling optimal compatibility and performance within Databricks.
Query Migration and Refactoring
The migration of queries involves both data transformation queries and ad hoc analytical queries. Here’s a breakdown of the main aspects to consider:
>>SQL query migration:
Automated Conversion: Use a Converter tool to automate the conversion of SQL from Redshift to Spark SQL, streamlining the migration process. Leveraging an accelerator, such as commercial static accelerators or advanced solutions like SunnyData’s LLM-powered accelerator, can further enhance efficiency and accuracy in complex SQL transformations.

Alternative Methods: While possible, custom script development or manual conversion are less recommended due to the increased effort and risk of inconsistencies - (not recommended)
>> Stored procedure migration:
Databricks does not have a specific object for stored procedures, but they can be created in Databricks Workflows as tasks.
Transform Redshift SQL patterns to Databricks SQL or PySpark to maintain functionality such as conditional statements and exception handling.
>> Considerations for common database objects and SQL patterns:
Python UDFs can be easily migrated, while Java UDFs need to be converted to SQL or Python.
Recursive CTEs and multi-statement transactions require custom solutions in PySpark and Delta Lake.
Migration Validation

Validation is critical to ensure that the data in Amazon Redshift and Databricks match after migration. Since the number of tables migrated can be very high, manual comparison of values is unfeasible. For this, it is recommended to implement an automated testing framework that compares data on both platforms. At SunnyData we have an accelerator for the validation and comparison of data automatically that saves a lot of time.
Validation points:
Table existence verification: Check that all required tables have been created in Databricks.
Row and column count: Compare the number of rows and columns in each table on both platforms.
Sum of numeric columns: Calculate and compare the sum of values in numeric columns to ensure consistency.
Count of distinct values in text columns: Evaluate and compare the number of unique values in text columns.
Running parallel tests:
Run pipelines in parallel on both platforms for a period of one to two weeks to monitor and compare results.
This section ensures that data is migrated correctly and synchronized, minimizing the risks of inconsistencies and errors in the migration.
Seamless Integration of BI and Downstream Applications: Phase 5
The last step in the migration process is integrating downstream applications and BI tools into the new Databricks Lakehouse environment. Many organizations consolidate their data warehousing needs within Databricks SQL, which not only provides exceptional price and performance for analytics but also supports high concurrency and autoscaling SQL warehouses. Databricks SQL’s Photon engine further enhances performance, using vectorized processing for fast, efficient queries.

After data and transformation pipelines are fully migrated, ensuring continuity for downstream applications and data consumers is essential. Databricks has validated seamless integrations with widely-used BI tools, including Sigma, Tableau, Power BI and more. To switch BI workloads smoothly, repointing dashboards and reports is often as simple as updating data source names to the new Databricks tables, especially when schema consistency is maintained. If schema changes are necessary, tables and views in Databricks can be adjusted to match expected formats for BI tools.
Testing is crucial: begin with a small set of dashboards to verify smooth functionality and iterate through the rest as needed.
Conclusions and Next Steps
We’ve reached the end of this blog, and the truth is that it’s challenging to cover such a broad migration process in a concise and well-structured way for readers. In upcoming blog releases, we’ll delve deeper into specific aspects of the migration to provide even more valuable insights for our readers.
Thank you to everyone who read through to the end of the article!