How to Migrate Databricks from GCP to Azure or AWS
The concept of scalability, in my opinion, is not limited solely to a solution’s ability to handle an increase in workload without compromising performance. It also means that the solution should be easy to manage as its usage grows. In the context of this blog, scalability implies that the solution can extend to other cloud platforms or facilitate its migration when needed.
To achieve this level of flexibility, it is essential to follow best practices and leverage tools that automate the deployment and configuration of components. Databricks is a cloud-agnostic platform, but in order to pivot between cloud providers, using accelerators like Terraform is crucial, as it streamlines the deployment process in the new destination.
What motivations might we have for leaving a cloud provider?
Although changing cloud providers is not very common today (it may become more frequent in the future as competition among cloud providers increases), there are certain situations that could motivate such a change. In this article, we’ll mention some of the most common scenarios:

Cost competitiveness: A provider may become less competitive over time. For example, Databricks tends to be more cost-efficient on Azure and AWS.
Strategic shifts: A new director may prefer a different cloud provider or take advantage of incentives and benefits offered by another provider, such as credits.
Multi-cloud and disaster recovery: There may be a need for a multi-cloud setup with high availability and disaster recovery capabilities.
How to approach a migration between cloud providers
In this blog, we will specifically focus on the migration and replication of Databricks resources, such as clusters, jobs, repositories, and others. While we will briefly touch on aspects related to data migration, managing dependencies with external services and integrations, as well as configuring permissions and security, we will cover these topics at a high level, since they have been discussed in detail in other blogs.
We also won’t delve deeply into business strategies or project management aspects, but we can summarize the key principles with a recommendation to adopt a gradual approach. Instead of attempting to handle the entire migration at once, it is more effective to divide the process into manageable phases, focusing on specific use cases and migrating each component progressively. This allows for adjustments and optimizations to be made in each stage before moving on to the next.
To approach a cloud-to-cloud migration or implement a multi-cloud environment, it is crucial to use tools that automate infrastructure deployment. Terraform is highly recommended in the Databricks ecosystem for its ability to manage infrastructure as code.

Additionally, it offers pre-built solutions that optimize this process, such as the Databricks Resource Exporter, which simplifies the export and migration of resources.
Databricks Terraform Resource Exporter
It is a tool that helps export and migrate all resources from a Databricks Workspace from one CSP (Cloud Service Provider) to another. This tool generates Terraform configuration files (.tf) and an import.sh script to facilitate the import process. It saves a lot of time and reduces the need for manual tasks. However, there are three important considerations to keep in mind regarding this accelerator:
The process must be repeated for each Databricks workspace you want to migrate.
It is important to note that the tool is still in the experimental phase.
Some manual tasks are required, as explained below.
Essentially, the Databricks Terraform exporter scans all existing resources in the workspace, creating a .tf file for each resource type (e.g., users.tf, compute.tf, workspace.tf, secrets.tf, access.tf, etc.). Each .tf file stores all the information associated with the existing configurations.
In the following image, we can visualize the scanning and generation process:
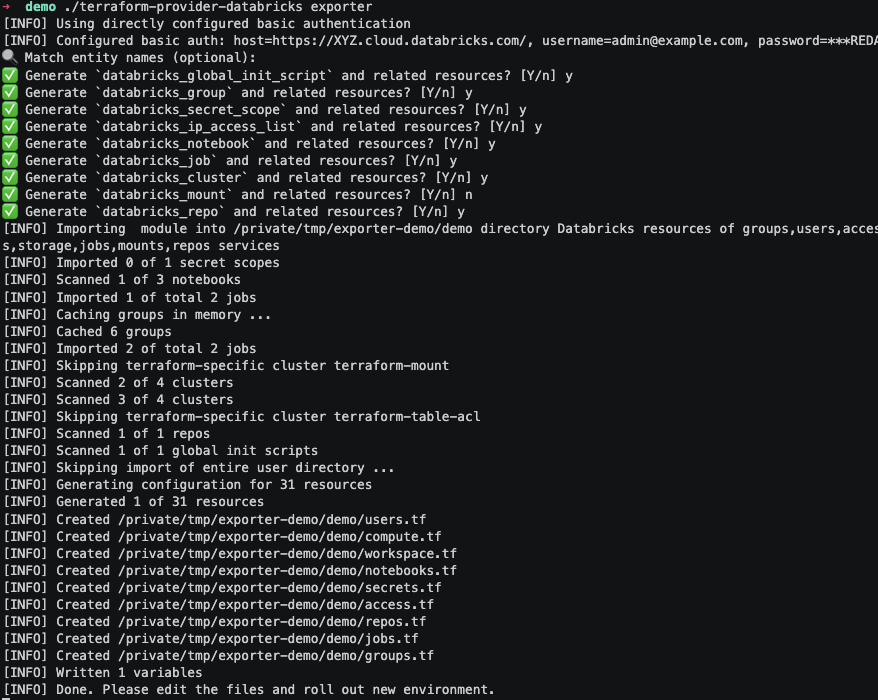
Afterward, each file must be manually adjusted to reflect the differences between providers, such as instance names or the availability of specific features in each region. For example, a compute instance in GCP has a different name in Azure or AWS, and certain functionalities, like SQL Serverless, are not available in all regions, even within the same CSP.
At SunnyData, we use LLM-based accelerators to automate and streamline these manual adjustments required in the .tf files. This allows us to further optimize the migration process, reducing the time needed to fine-tune configurations and enhancing efficiency when managing and migrating multiple Databricks workspaces.
Once the necessary adjustments have been made, the modified .tf files can be applied to the new cloud provider to recreate all Databricks resources. The import.sh script simplifies the process by running multiple Terraform import commands, saving both time and money.
Other Technical Aspects of Migration
To perform a complete Databricks migration, several components need to be considered beyond the infrastructure itself. Some of these include:
a > Stored Data: The data stored in Databricks (which is typically backed by GCS, S3, or ADLS) must be migrated separately. This can be done using methods such as:
AzCopy, AWS CLI, or similar tools to move data between clouds.
Using an ETL accelerator tool to facilitate the transfer of large datasets (*).
*Delta Live Tables (DLT) Pipelines: DLT pipelines require special considerations during migration. When migrating these pipelines between cloud providers, it’s essential to ensure that the state and checkpoints are properly managed to prevent data loss or inconsistencies.
To achieve a successful migration of streaming DLT pipelines, you can:
- Restart the pipeline from the beginning: This ensures that all data is processed again, though it can be time-consuming and resource-intensive if the data volume is large.
- Adjust the initial run to use the current snapshot: Configure the pipeline to start processing from the most recent state, avoiding the need to reprocess the entire data history. This involves adjusting checkpoints and ensuring that data sources are synchronized in the new environment.
3. Manually moving data by utilizing scripts.
b > External Service Connections: You’ll need to review and adjust connections with external services (such as databases, APIs, or messaging systems). This includes updating credentials, authentication configurations, and API/service end-points that may change between clouds.
c > MLflow Models: Models stored in MLflow within Databricks must be exported and imported manually to complete the migration. Although Terraform resources like databricks_mlflow_experiment, databricks_mlflow_model, and databricks_mlflow_webhook help manage and migrate some aspects of experiments and models, they do not automatically handle the underlying artifacts (such as trained models or datasets). These will need to be migrated separately.
d > Cluster Metadata Adjustments: As previously mentioned, it’s important to reiterate that the files will need to be adapted to the characteristics of the new environment. This includes reviewing and adjusting cluster metadata, such as auto-scaling settings, storage configurations, and auto-shutdown policies. Each of these elements must be verified to ensure that the configurations are compatible with the resources available in the new cloud environment.
e > Security and Permissions: While the Terraform exporter handles some aspects of permission and security migration, such as ACLs and IAM-integrated access policies, advanced configurations (like custom roles or networking configurations such as VPCs, subnets, and firewalls) will need to be manually reviewed and adjusted to ensure they are properly adapted to the new cloud environment.
f > Auditing and Monitoring: For resources like Azure Monitor, CloudWatch, or Google Cloud Logging, these will need to be reconfigured in the destination cloud, as they are not specific to Databricks but are dependent on the cloud platform in which they operate. Similarly, cost thresholds and other standard cloud infrastructure settings will need to be re-established.
Conclusions
Migrating between different cloud platforms, even when using the same platform like Databricks, always presents a challenge that requires careful planning and proper management. However, it is a feasible process and can be highly beneficial, especially in situations where cloud credits have been acquired or must be consumed within a specific timeframe.
Over time, multi-cloud scenarios will become increasingly common, and we are confident that content like this blog will provide significant value to those who face these challenges.