From RAGs to Riches: Practical Tips For Your Journey
Introduction
In the previous article, we introduced the different use cases of Generative AI that are being applied and explains the potential of this new paradigm. Now we will focus on technically explaining what is done and what challenges are faced in these types of projects so that the reader has the ability to understand how they work, what challenges they have and, above all, know the different practices or techniques that can be applied.
Artificial intelligence has been democratized and this has allowed the community and companies to start creating a lot of great products and services for the benefit of everyone. However, this also has its negative side and that is that there is an abundance of information, a lack of specialized professionals and many projects that are not being well executed in a combination of selling generic proofs of concept and lack of “know-how” in Generative AI.
How to insert knowledge?
All the models that we have available today, called GPT, Llama, Grok, Gemini, Mistral, etc. and that are used for all use cases with Generative AI, have been trained up to a date (for example until September 2022) and with publicly accessible information. So, there are two ways to insert knowledge into Generative AI projects and cover this information GAP:
The 1st is the RA”G” (actually Retrieval Augmentation only, the G is for Generation and that is a later step, here we are talking about ingesting). Basically an attempt is made to correct the model by means of a data pipeline for context at the prompt from some data source. That is, the model is not touched, what is done is adding context to the prompt (similar to when we use ChatGPT and in the question, we copy current text, from which we ask something)

2. The 2nd, integrates knowledge updating weights in models through a training process with the new data. This is known as Fine-Tuning. This process is more complex, expensive, etc., but it may be necessary when it is necessary for the system to be highly specialized in a specific topic.

Technically it is “trained” using practices such as RLHF (reinforcement learning) and optimizers:
1) RLHF (Reinforcement Learning from Human Feedback)
a. For example, ChatGPT sometimes prompts the user to select between two options.
2) Optimizers (SGD, Adam, RMSprop)
a. They are specific algorithms used to minimize the loss function during training of a model. All of them are based on gradient descent. SGD is simple but effective, while Adam and RMSprop can be more computationally intensive but often converge faster.
A short example
The following example will help you understand the concept of RAG and Fine-tuning. Imagine that your boss asks you to prepare a report on artificial intelligence. Now, consider these two options:
The first is to try searching for books, blogs or documents and generate the report based on the information collected. This is what a RAG does, it has not been trained with that information, but rather it acquires that knowledge by consulting data sources.
The second option is to study, incorporate that knowledge and become an expert in artificial intelligence. We are able to create the requested report with our knowledge. This is fine-tuning.
Which is better?
Given the similarity between AI and us the answer is very obvious, it depends. To create an article for a company that is not dedicated to that, it is enough to search for information and do our best (in the end, we have a “base” capacity like these AI models to generate an interesting article, there is a reason now. models are “smart”). Now, if we work in a company that specializes in AI, it may be better to do Fine-tuning.
Now, the nature of communication and information demands mixed scenarios. This blog, for example, is a mix of RAG and Fine-Tuning. I have acquired knowledge on the topic as a result of my experience but at the same time I have used information from the internet to prepare this blog with updated information that adds additional value.
This brings us to another point
It is crucial to know when to apply techniques: Prompt Engineering, Retrieval-Augmented Generation (RAG), or Fine-Tuning.

1) Prompt Engineering (*). This is always necessary when you are using an LLM to complete a task and it is ideal when the model has already trained with relevant data and just needs a little guidance to extract and present information.
2) RAG. The information is not in the training data original model, or updated information is needed. It is ideal for situations where the answer depends on the recent data or specific knowledge.
3) Fine Tuning. The model must adapt to specific domains, languages or styles insufficiently covered in his original training. It is relevant as there is an important change between the type of initial data of the model and what you will find in the final application.
(*) Prompt: In artificial intelligence, especially language models such as GPT, a prompt is a user-provided text input that initiates or guides the generation of a response by the model. It acts as an instruction or stimulus for the model to generate relevant and coherent content
Simplified Rag Scheme
Now, let's get back to the RAG. A RAG has two “parts”. The first is data ingestion, that is, the addition of knowledge as we mentioned without touching on the LLM model to use (we could alternate between any). The second is the recovery of that information when a query or task is performed, and the consequent generation of the response.

1) Data Ingestion: A common use case is collecting large amounts of textual data and preparing this data for model training. This includes Clean and normalize text, tokenize, and apply engineering techniques to transform text data into a format that the language model can understand and learn.
2) Data Query:The consultation process involves asking questions that the model answers based on data obtained during its training or from external sources. Retrieval is the ability to access that information and synthesis is the ability to combine and reformulate that information to produce a coherent and often creative response.
In summary: The document is ingested, information is retrieved according to the question and then the answer is generated (known as synthesis).
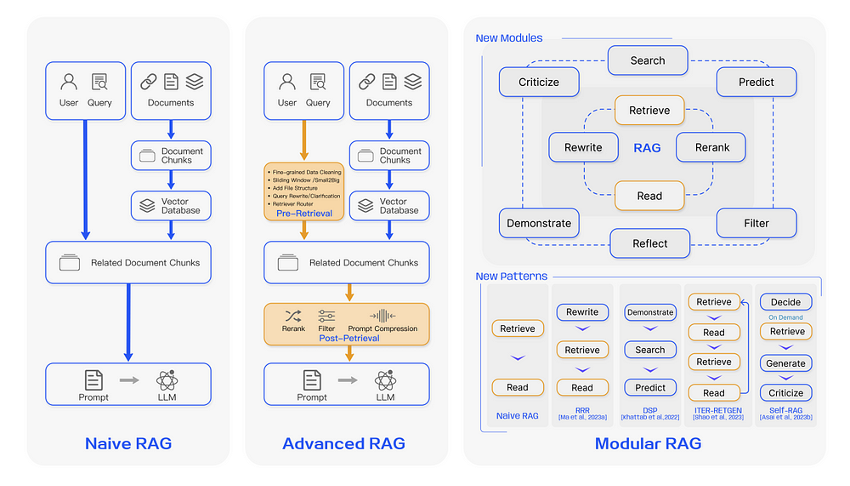
The “RAGs” and The problems with RAG Naive
Well, it is important to keep in mind that there are different types of “RAGs”. They all have the same purpose, just one more advanced than the others. In this article we are not going to complicate the reader with each of them, it is only important to know that 1) there are techniques (simple and complex) that can be applied to evolve RAGs, 2) the majority of projects that are seen are “RAG Naive ” and here we will focus on how we can improve them to take them to the next “Advanced” level.
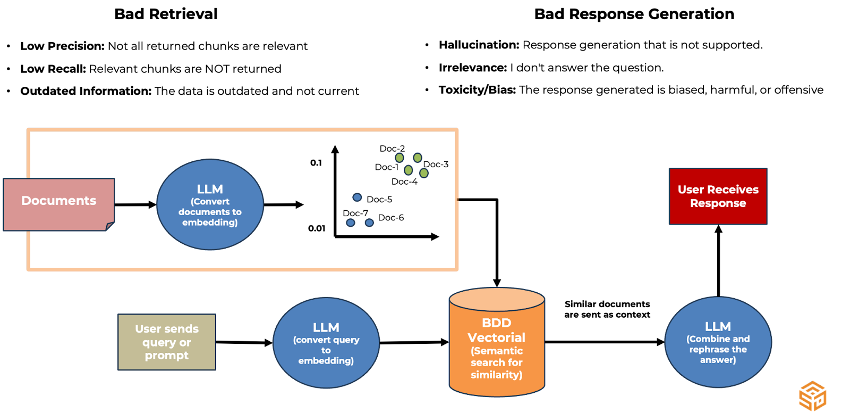
Naive RAGs can have many problems, which are solvable if the systems were built and ingested from the beginning with a good framework and knowledge of Generative AI. Some of the challenges that RAGs have are poor recovery (data ingestion phase) and poor response generation (data query and response generation phase)
What can we do?
In short, what you need to do is evaluate. To do this, it is important to test the system's ability to recover information. This is done by comparing the information returned by the system with what it “should” have recovered. Likewise, end-to-end evaluation must also be carried out that also includes response generation.

On the other hand, there are an infinite number of techniques that allow you to improve the performance of the system. Next, we will explain two of them super simple, which paradoxically are rarely applied.
Basic Level: Chunk Sizes
Changing the size of Chunks (how documents are partitioned when loaded into a database) can quickly improve the accuracy and relevance of the information that is retrieved.

Basic Level: Metadata Filtering
Likewise, the use of metadata helps a lot in retrieving information with precision and relevance. These systems are intelligent and capable of managing our language quite well, but if we help them they work much better. When metadata is not managed correctly and information is not tagged correctly, incorrect responses can be generated (imagine if we are working with documents or standards that are continually updated).
It is easier (and computationally cheaper) to consult only those documents that are required and also avoids generating responses with inadequate or outdated information. When this technique is not applied, we have the risk that the system uses information that is no longer valid to generate the response and we take it as valid. It is for this reason that data processing and intelligent management of RAGs are key. Credibility depends on its good use.

Why use Open Source LLM
Finally, to conclude this blog, we wanted to close by talking about Open Source models. At SunnyData we have an agnostic approach in this aspect and develop solutions that can be adapted to any type of model. In the end we are in a science in continuous evolution, but we recommend always paying attention to open models, since even if they are not in their base version better than GPT-4 (today the market leader in April 2024), well used they adapt better to the business when the business requires that degree of specialization

Some of the benefits:
• Transparency:A better understanding of how they work, their architecture and the training data used.
• Fine-Tuning: They allow fine tuning, adding specific data for each use case
• Community:They benefit from the contribution of people with different perspectives.

Last week, Databricks launched a new model (DBRX) of its own that defines a new state of the art of the open-source model community and surpasses previous ones in performance
At SunnyData, we will dedicate a blog to this new technology once we test it enough.
Our Conclusion
We hope that this blog has been to the reader's liking, but we are convinced that it will help a lot to understand about RAG, Fine-Tuning, how to do better projects, and, above all, to democratize knowledge. We look forward to seeing you next week with more content. Thank you!